
摘 要:针对基于虚拟输出排队的输入队列交换机应用于控制网络所存在的诸多困难,提出了一种新的输入队列交换机结构,并根据新的结构设计了一种基于记录矩阵和需求矩阵的信元传输顺序控制方案,以解决交换机中存在的信元行为及时延的不确定性问题。交换机采用两级调度机制,链接调度提供分级服务,交换调度实现端口匹配,以适应控制网络的流量特征。
关键词:交换式以太网;控制网络;调度
1 引言
目前的商用交换机提供的是尽最大努力的服务,不能提供实时保证。在诸多改进措施中,位于网络交换节点的通信控制策略是最直接有效的,即通过改进以太网交换机的调度机制,使其能服务于控制网络。而这方面的研究多以输出队列(OQ,Output Queue)交换机为改进对象,交换机被看成一个简单的队列系统,通过应用各种基于队列的调度算法或其改进算法来为不同实时需求的数据传输提供服务[1-3]。然而OQ结构的可扩展性较差,目前的高速交换机一般采用基于虚拟输出排队(VOQ,Virtual Output Queue)的输入队列(IQ,Input Queue)结构。另外,高性能的IQ交换机通常采用阵列式交换结构(Crossbar)来实现并行处理以及信元(cell)模式来简化调度逻辑。由于输入输出竞争的相互影响,IQ 调度是一个二维调度问题,与一维的OQ调度有着本质区别。在IQ 交换机调度策略的研究中,一般把交叉开关看作一个二分图,通过调度算法使得二分图边数或边的权重之和达到最大或极大。最经典的匹配调度算法是McKeown.N[4]提出的iSLIP 算法,已被广泛地应用于各种商用交换机中。此外原始的iSLIP 机制也历经了若干修改,衍生出了加权iSLIP 算法、优先级iSLIP算法等。不少学者从不同的角度对iSLIP算法进行了改进,研究出了许多各具特色的类iSLIP 算法。如Rostami.M.J 等[5]提出的FRGA 算法和Roidel.C 等[6]提出的iCFS 算法实现了更好的调度公平性,Wang.P等[7]提出了适用于流量负荷较大情况的iTFF算法,Li.Y.H等[8-9]的HE-MLWM、HE-WiSLIP和HE-iSLIP算法以及Chen.K.F等[10]的单次迭代SRA算法降低了匹配算法的开销,Kumar.A 等[11]则提出了可应用于iSLIP交换机的集成调度和缓存管理策略iSMM。但正如熊庆旭[12]所指出的,由于输入输出竞争之间的相互关联和制约,iSLIP算法及其类、衍生算法以及当前的基于分组(cell-based)的算法很难实现确定性的QoS保障。一个改进措施是引入优先级服务策略,如P-iSLIP 算法、Yi.P 等[13]提出的 PWDRR 和 CPRR 算法,它们可以提供某种程度的分级服务(CoS,Class of Service)和调度公平性,但是仍然无法消除通信的不确定性,难以应用于工业通信。Wang.Q.X 等[14]提出了一种适用于实时工业网络的IQ 交换机,它采用了结构性(frame-based)的调度算法来实现确定性QoS 保证,但是,该交换机结构中的Per-flow 缓存机制增加了VOQ管理以及匹配调度器对信元提取的难度。除了上述算法,另一类在交换机研究中涉及较多的是单纯的RR(Round Robin)类算法及变体。RR算法比较简单,但由于匹配矩阵及调度顺序完全预先确定,无法灵活应对信元的动态到达情况。当前关于IQ 交换机在控制网络中应用的研究还较缺乏,其相关研究很少涉及对信元传输顺序的有效控制和对周期性流量的支持。本文将针对IQ交换机应用于控制网络所存在的诸多困难,提出一种新的IQ 交换机结构及其调度机制。
2 面向控制网络的分级调度机制
本文在基于VOQ 的IQ 交换机中采用分级调度机制来为控制网络的数据通信提供确定性保证,包括两级调度:链接调度和交换调度。链接调度为各类数据分配不同的带宽,提供CoS,交换调度实现输入输出端口匹配。熊庆旭[12]指出在VOQ中提供确定性QoS保障必须保证任意端口对在任意时段中的最小服务量:输出端口必须提供传输带宽的保证,即在适当的时间与相应的输入端口匹配,而当输出端口提供了匹配时,相应输入端口中的分组要赢得输入竞争,使用传输机会。Cell-based 算法要完成这个协调是相当困难的,因此它所提供的主要是尽最大努力服务。本文的交换调度将若干时隙组成一个frame,作为一个整体来调度,frame 长度为一个交换机周期。所提出的基于VOQ 的IQ 交换机结构模型及其调度机制如图1所示。
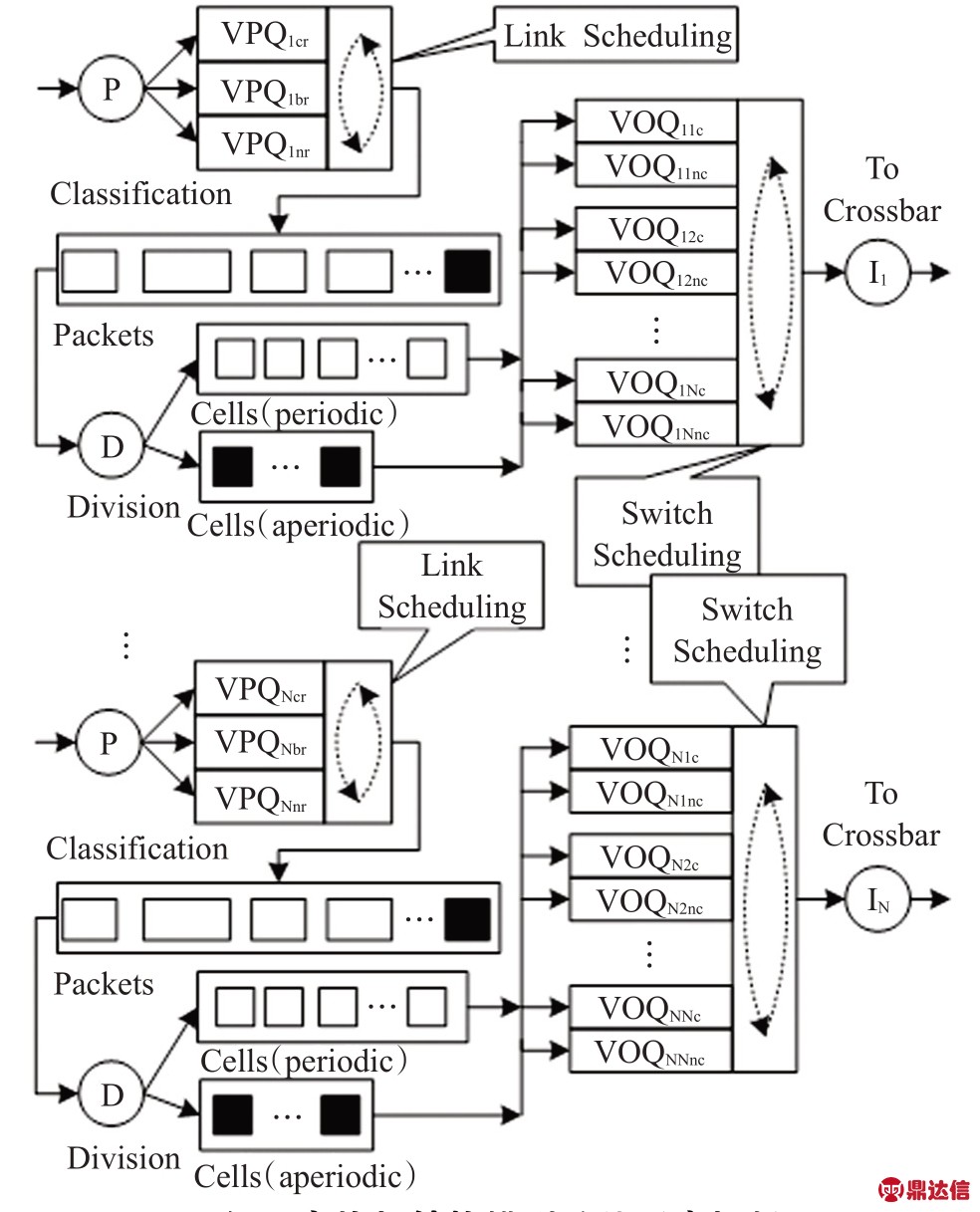
图1 交换机结构模型及其调度机制
在每个输入端口的VOQ队列之前设置了三个优先级队列VPQ(Virtual Priority Queue),以端口1 为例,交换机根据到达数据包的优先级字段的值来将其进行分类,分别放入周期性实时数据队列(VPQ1cr)、突发性实时数据队列(VPQ1br)和非实时数据队列(VPQ1nr)中。而后通过链接调度,按照每个VPQ优先级的不同,为各类数据分配不同的带宽。为了简化后面的交换调度逻辑,数据包在进入VOQ 之前被划分成定长的信元,并根据数据包的优先级将信元区分为周期性信元和非周期性信元。信元依据其目的端口地址进入对应VOQ。而每个VOQ 由两个子队列组成:VOQxyc和VOQxync(x、y 分别表示源端口号和目的端口号),分别对应周期性数据子队列和非周期性数据子队列,不同类型的信元进入相应的子队列。在此过程中,分别记录周期性信元和非周期性信元进入的顺序,并将每交换机周期内的记录转换为需求向量,每个端口的需求向量便组成了该周期内的交换调度需求矩阵,再依据交换调度算法得出相应的调度矩阵,输入输出端口形成匹配。
3 基于优先级的带宽分配策略
在输入端对数据包进行链接调度的目的是使交换机能够区分周期性实时数据、突发性实时数据和非实时数据,并对进入VOQ的各种流量带宽进行控制。
3.1 队列结构
在基于VOQ结构的交换机中,一方面,为了支持优先级,每个输入端口需要为不同类型的输入数据配置不同的优先级队列,另一方面,VOQ体制要求每个输入端口为每个输出端口配置缓冲队列。为了将二者有效融合,考虑如下几种队列结构的设计方案。
如图2(a)所示,前面提到的P-iSLIP就是基于这种队列结构。每个输入端口的每个VOQ被分为K个子队列,其中K 为优先级数目,VOQijk表示由输入端口i 发送到目的端口j 的优先级为k 的数据队列。这样每个输入端口的队列数为N×K 个,而调度算法就必须在N×K个队列中进行裁决。为了提高调度算法的效率,考虑如图2(b)所示的级联队列结构。在这种结构下,每个输入端口配置了N 个VOQ,VOQij表示由输入端口i 发送到目的端口j 的根队列,每个VOQ 之前又设置了K 个子队列VPQ,用于提供优先级机制,VPQijk表示了由输入端口i发送到目的端口j的优先级为k的子队列。在该结构下,调度算法只需要在N+K个队列中进行裁决,另外该结构并行性好,且很好地分离了不同优先级队列的带宽分配算法和输入输出端口的匹配算法。但是,在该结构中,无论采用何种带宽分配算法,对信元传输顺序的控制都较为困难和复杂。为了消除信元传输顺序的不确定性,本文提出如图2(c)所示的队列结构,该结构是对图1的简化。该结构并不为输入端口的每个VOQ队列设置1~K个VPQ,而只为每个输入端口配置一套VPQs,VPQik表示输入端口i 优先级为k 的数据队列。而每个VOQ只对应两个子队列,VOQijc和VOQijnc,表示端口i到端口j的周期性数据和非周期性数据。该结构在简化了队列机制的同时,也为信元传输顺序的控制提供了解决方案。

图2 几种队列结构设计方案
3.2 优先级区分
为了使交换机能够区分流量级别,需要在各节点和交换机中引入IEEE802.1p 优先级协议,它是IEEE 802.1Q 标准的扩充协议,根据IEEE802.1Q 规范定义的扩展以太网帧结构,设置TCI 字段的前三位。若是三层交换机,优先级标注的位置一般在IP层,此时设置TOS字段的前三位。
3.3 链接调度
到达输入端口i 的数据经过分类后进入相应优先级队列,各队列中仍采用先来先服务机制,但在多个队列之间需要进行调度,高优先级的数据将获得更多的交换机周期份额。这属于基于队列的调度算法问题,从公平性和延迟属性上来看,基于GPS(Generalized Processor Sharing)的方法是最理想的调度算法,但难以实现。而基于RR的调度算法不需要进行时标比较,但存在时间不确定性,如DRR(Deficit RR)算法。在本文提出的二级调度结构中,链接调度、数据包分割、匹配调度和数据包重组需要遵循交换机周期工作以避免不同步。另外,由于是变长分组的队列,调度算法需要同时考虑分组大小和数据流权重的不同。
设交换机周期被划分为了M个信元时间,cell表示一个信元时间;Wi表示队列i在一个周期内的发送配额,即Wi个信元时间,根据一个交换机周期内的带宽资源和优先权比例来为各队列设定Wi;Di表示每次轮转中队列i 的发送余额;T 表示一个周期内所剩余的总信元时间;List为所有在某一周期内竞争接受服务的队列列表。
当一个新的周期开始时,T=M,所有队列均被添加入List,各队列的Di初始化为Di=Di+Wi。调度器总是在List 中找出所有非空队列中优先级最高的队列i,对其进行服务,队列i中的数据包依次被发送,每发送一个数据包,Di=Di-x,T=T-x,x 为每次发送数据包的长度(不定)。若在此发送过程中,检测到队列i 为空,则转向对List 中所有非空队列中优先级最高的那个队列的服务;若队列i当前的队头数据包长度大于Di时,说明队列i的发送余额不足以发送队头数据包,该队列在本周期内的服务结束,则将该队列从List中移除,并转向对非空队列中优先级最高的那个队列的服务;而若队列i当前的队头数据包长度大于T,说明在该周期内无法完整发送该数据包,该队列在本周期内的服务结束,则将该队列从List 中移除,并转向对非空队列中优先级最高的那个队列的服务。若在对队列i的服务过程中,某更高优先级的队列j 有数据包到达,调度器在队列i 发送完一个完整数据包之后转而对j进行服务,即遵循非抢占式的优先权策略。
4 信元传输顺序的控制
对信元传输顺序的控制是保证两级调度协调工作和通信确定性的关键。前面提到,VOQ 的关键问题就是对信元传输顺序的控制较为困难和复杂,单纯地基于优先级或者基于RR 的调度策略均不能解决这一问题。一个常用的做法是为数据包打时间戳,而后通过时标比较对缓冲区重排,但这种方法开销大且难于实现。本章将介绍一种控制方案来免于这些操作。设周期性实时数据、突发性实时数据和非实时数据三者所获得的交换机周期(长度为M)份额分别为 Wcr、Wbr和 Wnr。
4.1 记录向量和记录矩阵
记录向量记录一个交换机周期内信元的到达情况,它由周期性信元记录向量和非周期性信元记录向量组成。对于周期性信元,只需要记录发往各输出端口信元的数量,无需记录它们的到达先后。在一个周期内,不同优先级VPQ 内的数据包经过链接调度被分配以相应的带宽,而分割模块将数据包分割并区分为周期性信元和非周期性信元,再按照信元的目的地址送入相应的VOQ内,在此过程中,分别记录周期性信元和非周期性信元的到达情况,记录向量的内容为信元的目的端口号。每一个输入端口对应一个记录向量,若N 为端口数目,对全体输入端口,在一个周期内,取周期性信元记录向量(长度为Wcr)和非周期性信元记录向量的前Wbr+Wnr长度便组成了该周期内的记录矩阵,该矩阵为N×M矩阵,每行代表一个输入端口,每列代表一个信元时间。
4.2 需求向量和需求矩阵
需求向量是匹配调度逻辑的输入,其长度为M,它告诉某输出端口在这个周期内,哪些输入端口的信元将要传送到该输出端口。需求向量的内容为信元的源端口号,每一个输出端口对应一个需求向量,所有的需求向量便组成了一个周期内的需求矩阵。需求矩阵也为一个N×M 矩阵,每行代表一个输出端口,每列代表一个信元时间。
4.3 从记录矩阵到需求矩阵
需求矩阵根据记录矩阵而生成,若记录矩阵中的元素进入需求矩阵,那么它们将从记录矩阵中被删除。对于N×Wcr的周期性需求矩阵的生成,只需要计算各输出端口号在记录矩阵中出现的次数和所在行号,无需关心它们出现的先后顺序,而后将行号填入需求矩阵中该输出端口号对应的行里即可。而对于非周期性需求矩阵的生成,由于非周期性数据具有不确定性,无法保证一个周期内非周期性数据的到达特性。因此可能会出现无法将记录矩阵中的所有元素全部导入需求矩阵的情况,这时可将超出匹配调度的可调度条件限制的元素保留在记录矩阵中,在下一个时钟周期内,被延迟的元素将被优先导入需求矩阵。
4.4 有效需求矩阵
无论是记录矩阵、需求矩阵还是后面将要讨论的调度矩阵,均被划分为了周期性和非周期性两类,这么做的原因是:控制网络中的周期性数据具有可预测性,易进行可调度性分析,满足可调度性条件的需求矩阵即为有效需求矩阵,有效需求矩阵一定可以通过匹配调度算法求出一个本周期内可行的调度矩阵。而非周期性数据则无法预测其到达情况,二者同时考虑将无法保证每个周期的需求矩阵都满足可调度性,而且很有可能使得周期性实时数据被延迟,所以需要把它们区分处理。链接调度中已经为两类数据分配了不同的带宽,在向控制网络添加周期性实时任务的时候,需要考虑剩余带宽是否还能满足新添加的任务。判断一个需求矩阵是否为有效需求矩阵,可根据如下准则:记录矩阵中任何一个输出端口号出现的次数均小于等于M,则由该记录矩阵推得的需求矩阵为有效需求矩阵或称该需求矩阵是可调度的。与周期性需求矩阵在每个时钟周期内均保证为可调度的不同,非周期性需求矩阵可能出现在本周期内通过放弃部分信元的传送来将其转化为可调度的情况。
5 基于时间片的端口匹配策略
信元进入VOQs后,匹配调度逻辑根据需求矩阵的内容生成调度矩阵,由于此前很好地控制了信元的进入顺序,所以匹配调度逻辑可以准确无误地从各VOQ 中取得所需要的信元。在匹配调度中,一个交换机周期也被划分为了周期性信元调度时段和非周期性信元调度时段。匹配调度通过调整一个frame内信元的传输顺序,建立无冲突的端口匹配。
5.1 任务需求的描述与转化
在控制网络中,周期性实时数据是占主导地位的,如传感器信号、视频监控信号等。在实际应用中,往往以某实时任务的周期为多少来描述。由于数据包在交换机内将被转化为信元,因此发送端将数据包长度定义为信元的整数倍,且各模块的工作周期总由一个最小的粒度时间单元构成,即为信元时间,因此,无论实时任务需求描述为何种形式,其在交换机中的实际周期总是为信元时间的整数倍,于是,设cell表示一个信元长度,cell-time表示信元时间。可以用一个二元组(1*cell,x*cell-time)来描述一个周期性实时任务,即该实时任务在x个信元时间内发送1个信元。上面是对任务周期的直接转化,实际应用中,实时任务可能更多地表示为(y*cell,z*cell-time),即在z个信元时间内发送y个信元,如某周期性任务每z时间间隔发送1个数据包,数据包为y个信元长度。在这种情况下,可将具有(y,z)形式的描述转化为![]() 。交换机时钟周期为M个信元时间,因此还需要以M 为基准对任务需求进行进一步的转化,即转化为1个交换机时钟周期内发送n 个信元的形式。对于具有(1,x)形式的任务,将其转化为
。交换机时钟周期为M个信元时间,因此还需要以M 为基准对任务需求进行进一步的转化,即转化为1个交换机时钟周期内发送n 个信元的形式。对于具有(1,x)形式的任务,将其转化为![]() 。这样的规范描述和处理可以大大简化交换机内的两级调度以及数据包分割重组逻辑,并为统一两级调度的结果以及满足任务实时性的匹配调度算法的设计提供了前提。对于非周期性任务,其到达无规律可循,一个经典的处理方法是简单地把它们看成是周期等于最小间隔时间的周期性任务来考虑。
。这样的规范描述和处理可以大大简化交换机内的两级调度以及数据包分割重组逻辑,并为统一两级调度的结果以及满足任务实时性的匹配调度算法的设计提供了前提。对于非周期性任务,其到达无规律可循,一个经典的处理方法是简单地把它们看成是周期等于最小间隔时间的周期性任务来考虑。
5.2 调度矩阵
调度矩阵是端口匹配的依据,根据每个周期内的需求矩阵推得。调度矩阵为一N×M 矩阵,它同样被分为了周期性和非周期性两部分,不过,由于此前在记录矩阵向需求矩阵的转化过程中已经考虑了可调度性且对二者采用了不同的转化策略,因此在这里无需再对二者区分说明,输入给匹配调度逻辑的均为有效需求矩阵。调度矩阵的每一行代表一个输出端口,每一列代表一个信元时间。调度矩阵的元素和需求矩阵一样,均为输入端口号,其中第i行第j列的元素k 代表在某周期的第j 个信元时间,输出端口i与输入端口k匹配,当第i行第j列的元素为0时,代表在第j 个信元时间,输出端口i 空闲。一个合法的调度矩阵要求:每列中的非0 元素互异,即在同列中没有相同的输入端口号。其物理意义也很明确:在某周期的一个信元时间内,不允许一个输入端口收到多个输出端口的Grant。注意,一个需求矩阵可能的调度矩阵并不唯一。
5.3 匹配调度
匹配调度算法的工作就是在每个周期开始时的配置阶段,置换需求矩阵每行中的各个元素,使得形成的调度矩阵的每列中没有输入端口号冲突。本文提出分层的匹配调度算法nLA(n-Layer),其中n代表算法设置的层数。层数n设置的越少,调度成功率越高,但算法复杂度也越高,在实际应用中,需要根据硬件情况来设置n。
5.3.1 辅助项
(1)调度矩阵:为一N×M矩阵,设为A,用于存储匹配调度结果。
(2)现状矩阵:为一N×M矩阵,设为B,其元素bij与调度矩阵各元素一一对应,bij 只取1 或者0,代表输出端口i在信元时间j内忙或者空闲。
(3)可用信元时间记录数组:在针对某个端口号进行调度时,为其保存一个可用信元时间记录数组JNM,它将某端口号已经使用的信元时间设置为1。
(4)调度矩阵每行剩余信元时间:设Li 表示第i行剩余信元时间,其初始值为M。
5.3.2 影响调度率的几个因素
(1)需求矩阵各输入端口号行出现频率:设输入端口k的行出现频率为 fk,fk 越大,端口k越优先被调度。
(2)需求矩阵各输入端口号在某行中的出现频率:设 表示输入端口号k在第i行出现的频率,
表示输入端口号k在第i行出现的频率, 越大者越优先被调度。
越大者越优先被调度。
(3)调度矩阵中各输入端口号在每行的剩余非冲突信元时间:设 表示输入端口号k在第i行的剩余非冲突信元时间。
表示输入端口号k在第i行的剩余非冲突信元时间。 的初始值
的初始值![]() 越小者越优先被调度,
越小者越优先被调度,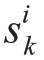 在不断变化,一般情况下
在不断变化,一般情况下 的表达式,
的表达式,![]() 。
。
5.3.3 分层调度的思想
首先需要对需求矩阵中的信息进行提取,定义一个四元组(port,line,t,s),其中,t、s 分别代表输入端口号port 在行line 中的出现频率和剩余非冲突信元时间。一个N×M的需求矩阵可以提取出N×N个这样的四元组元素。
下面需要确定这N×N 个元素的优先级顺序,而后根据调度算法设置的层数将它们安排在相应的优先层级内。如前所述,层数n的确定可以根据实际情况,可以从1~N×N,随着层数的增加,调度成功率和算法复杂度随之降低。对于5.3.2节提到的影响匹配调度成功率的三个因素,最理想的情况就是依据因素3,每次从剩余未完成调度的元素中选择出s 最小的那个元素进行调度,可以达到最高的调度成功率,但复杂度较高,这种情况所对应的nLA算法的层数n为1。分层调度的目的正是为了通过设置层级,在调度成功率和算法复杂度之间进行折衷。为此,引入5.3.2节的因素1和2,这两个因素实际上为因素3所暗含,因素3 的计算和排序是主要的时间开销,而1 和2 则是固定值,只需要在开始遍历一次需求矩阵即可确定,因此将因素1和2作为分层的标准。
通过实验发现,因素1、2对调度成功率有着不同程度的影响,这里定义指标zs=(t/M)·(f/N),初始状态下,依据zs 值由高到低的顺序依次将元素排入各层,先排层号小的层级,层号越小则位于该层的元素优先级越高。算法将按照层号的大小顺序来调度各层元素。每层的各个元素也需要确定调度顺序,针对同一层元素,s值越小者越优先被调度。这一步骤是算法主要的时间开销,因此,在设置层数n时,需要控制每层的元素数,当层数n 设为N×N 时,每层的元素数为1,这样算法就退化为只考虑初始指标zs来确定调度顺序的静态算法,此时算法的复杂度达到最低。
匹配调度运行于每个交换机时钟周期的开始,而后输出端口根据形成的调度矩阵依次从相应的VOQ中提取信元。具体过程为:(1)Grant,输出端口向相应输入端口发出授权;(2)Accept:输入端口接受相应输出端口的授权,建立匹配关系。由于授权一定能被接受,也就省略了运行期间类似iSLIP算法多次迭代的操作。
6 实验分析与比较
本文的数值仿真实验用C/C++按前文建立的模型,分别实现了本文提出的算法和文献[14]的算法,然后在相同输入情况下进行了比较。
6.1 调度率

图4 交换机(16端口)中三种算法的调度率
实验旨在分析本文提出的分层的匹配调度算法nLA 的调度率,并与另一个结构性匹配调度算法LS算法[14]进行比较。实验过程中,取层数n=N×N 以及n=N ,分别对应N2LA算法和NLA算法,其中N为端口数。实验中,交换机时钟周期为1 ms,端口速率为10 Mb/s,交换机端口数N分别取8、16和32。分别针对LS算法、N2LA算法和NLA算法,在不同的交换机带宽使用率(交换机负载率)下,进行1 000 次试验,所得出的结果如图3~图5 所示。可以看出,N2LA 算法在同等负载情况下,相对LS 算法,其端口的匹配成功率得到了一定的提升,而NLA 算法则在同等情况下较大程度地提高了端口的匹配成功率。而在时间复杂度方面,三种算法的运行期时间复杂度同为O(1)。对于NLA 算法,随着层数的减少,算法的调度成功率增高,但配置期的时间复杂度也相应增高,N2LA算法的配置期时间复杂度与LS算法相同,同为O(N2M),而NLA 算法的配置期时间复杂度为O(N3M)。所以,在实际应用中,应根据硬件条件选择合适的NLA算法层数。
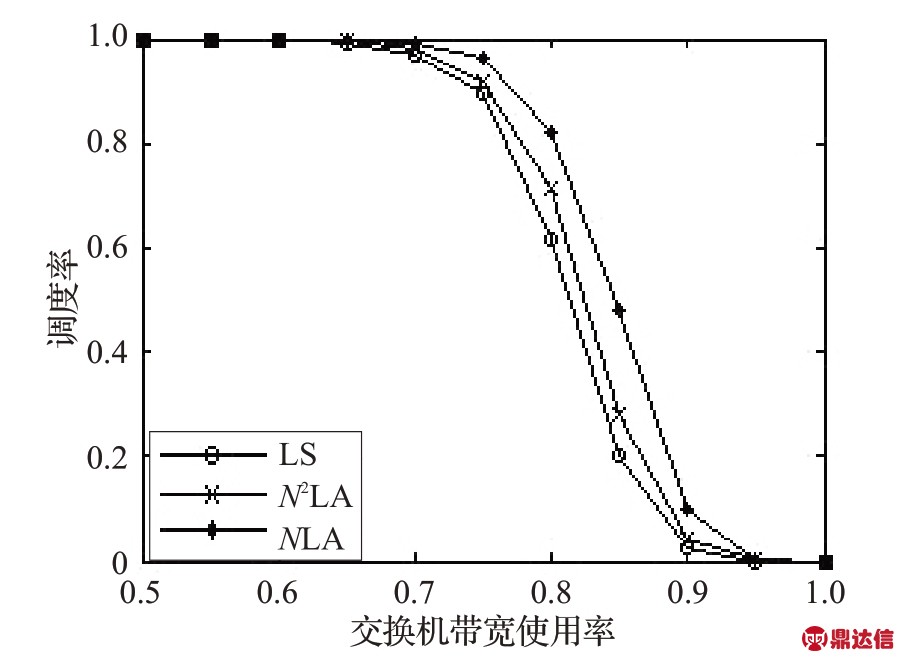
图3 交换机(8端口)中三种算法的调度率
6.2 时延上界
本节分析所提出的分级调度策略在不同交换机负载情况下的时延上界。控制网络中,典型的传感/执行数据流每10 ms发送1~5 kb信息,最大允许时延通常为50 ms,典型的实时视频数据流每30 ms 发送120~240 kb信息,最大允许时延通常也为50 ms[15]。
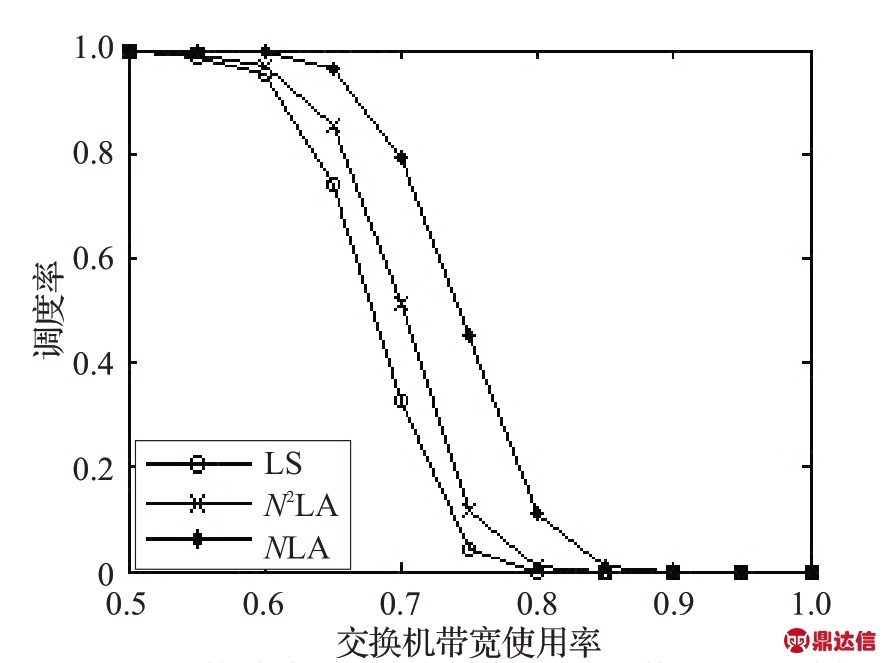
图5 交换机(32端口)中三种算法的调度率
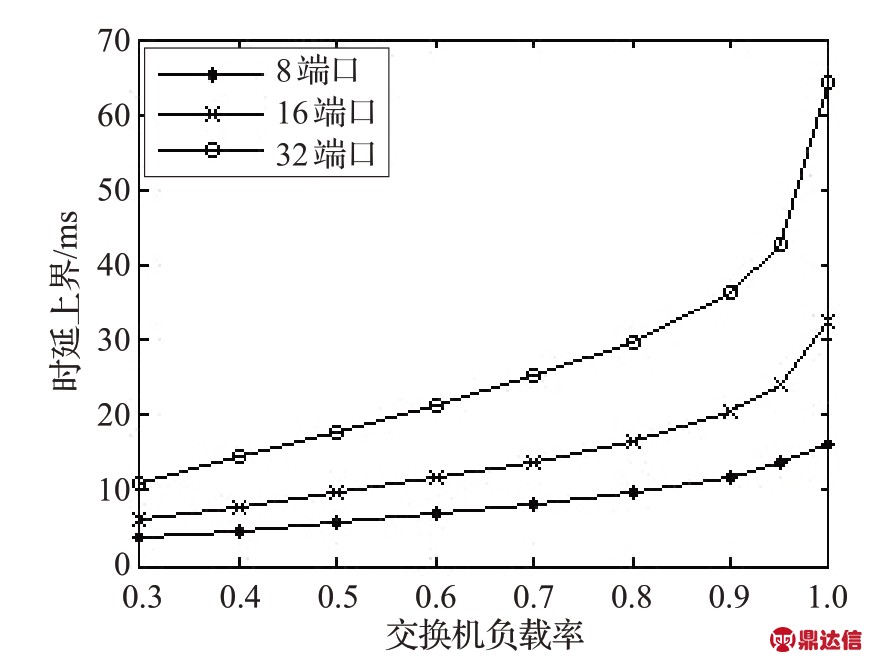
图6 端口速率为10 Mb/s的交换机时延上界
首先设交换机端口速率P 为10 Mb/s,控制网络中同时传送周期性实时数据、突发性实时数据和非实时数据,且周期性实时数据占有60%(ωp=0.6)的交换机带宽配额,分析过程中设所有信元均实现了匹配。利用确定网络演算理论中的到达曲线对周期性数据流的到达情况进行建模。设负载率RATE={0.5,0.6,0.7,0.8,0.9,1.0},持续传输信元数 n=P·ωp·RATE/(N·cell)·10-3,cell 大小设为 500 bit,则周期性实时数据流的持续传输速率参数为αˉ=n·cell/(1×10-3),而其爆发参数σ=min( )12 ·cell,n·N·cell 。此时,在不同端口数目下,时延上界随负载变化的情况如图6 所示。由图可见,大部分负载情况下(低于0.95),由本文所提出来的各种端口数目的实时交换机均能保证周期性数据的时延上界在50 ms以内。
下面提高交换机的端口速率P为100 Mb/s,交换机其他配置不变。此时周期性实时数据持续传输速率参数为 ˉ=n·cell/(1×10-3),而爆发参数σ=min(18·cell,n·N·cell)。在不同端口数目下,时延上界随负载变化的情况如图7所示。可以看出,通过提高交换机端口速率,利用本文所提出来的交换机结构可基本保证在各种端口数目情况下周期性数据10 ms 的实时要求,另外,相对图6、图7 中各端口数目情况下的时延上确界随负载的变化相对平缓。
ˉ=n·cell/(1×10-3),而爆发参数σ=min(18·cell,n·N·cell)。在不同端口数目下,时延上界随负载变化的情况如图7所示。可以看出,通过提高交换机端口速率,利用本文所提出来的交换机结构可基本保证在各种端口数目情况下周期性数据10 ms 的实时要求,另外,相对图6、图7 中各端口数目情况下的时延上确界随负载的变化相对平缓。
7 结论
研究了基于VOQ 的IQ 交换机结构及其调度机制。首先提出了一种新的交换机结构模型,该结构在简化了队列机制的同时,也为信元传输顺序的控制提供了解决方案。针对新的结构设计了相应的分级调度机制。对信元传输顺序的控制是保证两级调度协调工作和通信确定性的关键,为此,利用所提出的交换机模型设计了一种基于记录矩阵和需求矩阵的控制方案,实现了对信元行为的有效控制。
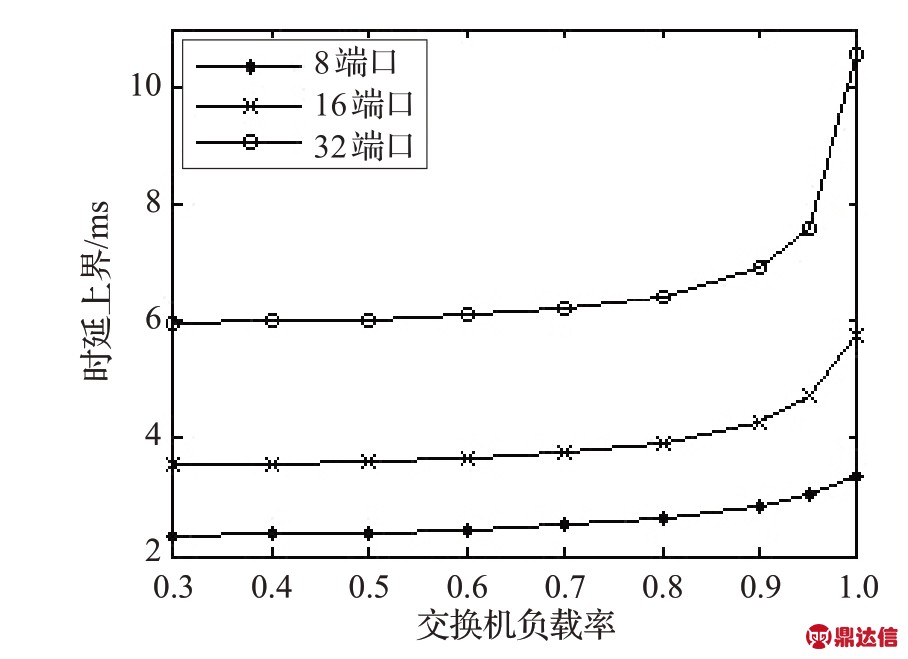
图7 端口速率为100 Mb/s的交换机时延上界


