
摘 要:对声音识别技术进行了深入研究,提出一种声音识别传感器设计。该传感器首先采集声音信号,经过整形、放大后进行A/D转换,提取语音特征,并利用动态时间规整(DTW)算法进行识别;传感器采用C/S架构和外部设备进行通信,通过串口接收外部设备命令,分析处理后传回识别结果。最后设计并实现智能家居硬件环境,通过声音识别传感器完成智能家居的远程遥控,完成诸如开灯、关灯等动作。实验结果表明:该传感器工作稳定,识别率高,能够应用于各种场合。
关键词:嵌入式系统; 智能家居; 声音识别传感器
0 引 言
随着传感器计算的快速发展,其在智能家居[1,2]中的应用日益广泛。声控装置是智能家居设备中重要组成部分,用户可以通过声音进行家庭设备控制。声音识别研究开始于20世纪50年代,BELL实验室开发了世界上第一个语音识别系统—Audry系统,可以识别10个英文数字。到20世纪70年代,声音识别技术得到快速发展,动态时间规整 (DTW) 算法、矢量量化(VQ)以及隐马尔科夫模型(HMM)理论等相继被提出,实现了基于DTW技术的特定人孤立语音识别系统。近年来,声音识别技术已经从实验室走向实用,国内外很多公司都利用声音识别技术开发出相应产品。
本文设计声音识别传感器,并将其融入到智能家居系统中,通过声音控制传感器来完成智能家居设备的控制,达到远程遥控家电设备的目的。
1 声音识别系统原理
声音识别传感器设计包括硬件设计和软件设计两个部分,其中软件设计部分的核心是声音识别算法实现。声音识别算法包括前端处理和后端匹配两个部分[3,4],如图1所示。前端处理包括预处理和特征提取,常用的特征包括短时均值能量、短时均值过零率、预测系数、倒谱、共振峰等。这些特征参数按照时间序列构成待测数据集,然后按照特定算法要求同参考模式进行匹配得到结果。目前比较多的模型匹配技术有DTW[5]、HMM和人工神经网络(ANN)等[6~8],本文以DTW算法为原型基础编程实现。
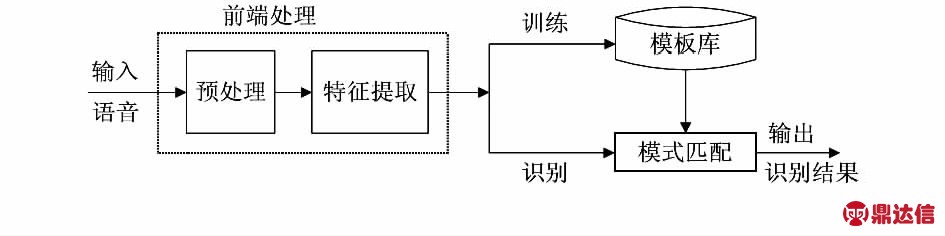
图1 声音识别系统原理框图
Fig 1 Principle block diagram of voice recognition system
2 DTW算法
DTW算法基于动态规划思想,能够解决发音长短不一的模板匹配问题,主要用于孤立词识别,是语音识别中出现较早而且极为经典的一种算法。声音识别参考模板为R={R(1),R(2),…,R(m),…,R(M)},其中,m为训练语音帧的时序标号,R(1)为起点语音帧,R(M)为终点语音帧;声音识别测试模板为T={T(1),T(2),…,T(n),…,T(N)},n为测试语音帧的时序标号,T(1)为起点语音帧,T(N)为终点语音帧。测量T,R的距离 D[T,R],距离越小,则相似度越高。DTW算法实现过程如下:
1)初始化,申请2个n×m的距阵D和d,分别为累积距离和帧匹配距离;
2)判断是否满足结束条件,若满足跳转到第5步;
3)计算X1=round((2M-N)/3))和X2=round((2N-M)×2/3);
4)根据X1和X2关系进行匹配计算;
5)输出累积距离D。
3 系统设计与实现
本文采用声音采集传感器、STM公司的STM32F103VCT6作为主要器件来设计声音识别传感器,系统构成如图2所示。系统由声音采集传感器模块、电源模块、串口通信模块、声音识别结果显示模块以及其它辅助电路组成。
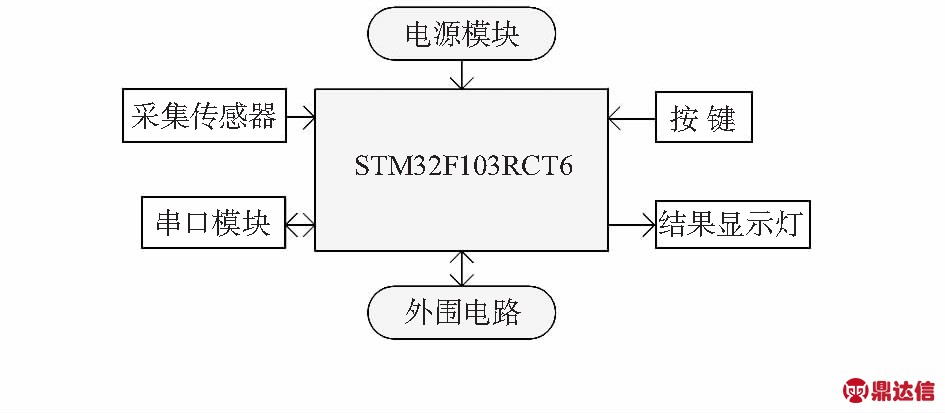
图2 声音识别传感器框图
Fig 2 Block diagram of voice recognition sensor
3.1 声音采集传感器
设计的声音采集传感器内置一个对声音较敏感的电容式驻极体话筒,当有声波时,声波推动话筒内的驻极体薄膜振动,导致电容的变化,从而产生微小电压信号。电压信号经过整形放大后送到A/D模块进行A/D转换,得到采集声音所对应的数字信息,交由处理器进行处理识别。设计的声音采集传感器性能指标为:测量范围为30~120 dB(A);频率范围为20 Hz~8 kHz;灵敏度为电压41.5 mV/dB,电流为0.133 mA/dB;最大误差为0.5 dB。
3.2 核心处理器与外围电路设计
本文采用STM32F103VCT6为核心处理器,该处理器为ARM 32的Cortex-M3核,最高工作频率可达72 MHz,性能达到1.25DMips/MHz,内部集成FLASH和RAM,并且有3个12位A/D转换器。该处理器功耗低,接口丰富,具有BSP库,易于快速产品开发和设计。
核心处理器外围接口电路包括电源模块、晶振模块、控制和显示模块、声音采集模块等。电源模块采用5 V直流电压输入;晶振模块使用8 MHz晶振和32.768 kHz晶振直接连接到处理器相应端口;控制和显示电路通过GPIO口和处理器进行互连;声音采集模块通过AD口连接到处理器。
3.3 通信模块电路设计
声音传感器和外部器件采用C/S结构,通过串口和外部器件相连。外部器件通过串口发送命令,声音传感器通过串口接收命令后进行解析、执行,并把结果反馈给外部器件。图3显示了声音传感器和PC通信过程。
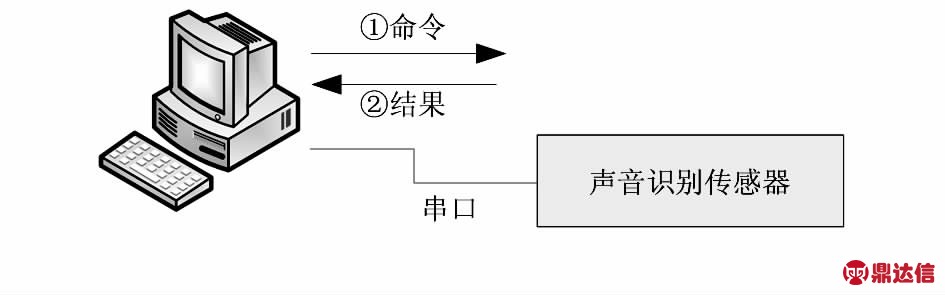
图3 声音识别传感器C/S通信
Fig 3 C/S communication of voice recognition sensor
由于外部器件串口电平多为RS—232电平,而声音识别传感器的处理器串口电平为TTL电平,因此,声音识别传感器内部采用MAX3232芯片进行电平转换。
3.4 软件编程与实现
声音识别传感器软件编程主要包括三部分:语音采集、训练和识别,详细步骤如图4所示。
1)语音采集模块:采集语音,并保存为“.wav”文件;
2)训练模块:对录入的语音进行预处理和Mel倒谱系数提取,形成语音模板并保存到指定文件中;
3)识别模块:对待测语音进行预处理和Mel倒谱系数提取,然后与保存的模板进行匹配,并把识别结果显示出来。
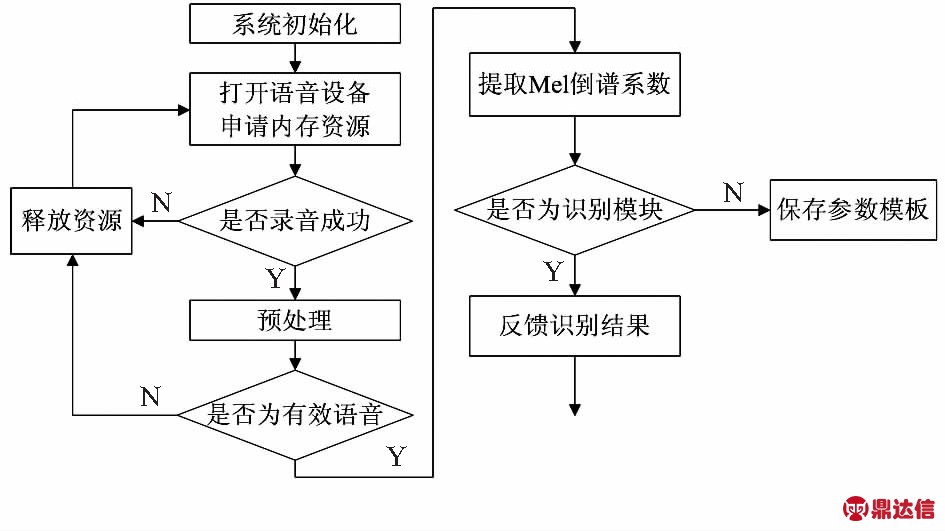
图4 语音识别模块软件设计流程
Fig 4 Software design process of phonetic recognition module
4 实验测试与结果分析
4.1 测试环境搭建
本文为测试声音识别传感器性能,搭建智能家居远程声控系统应用环境,如图5所示。测试系统包括声音识别传感器、Zig Bee无线传输网络以及家用电器控制平台。实验前假设用户声音特征信息已经存储在声音识别传感器模块中。实验步骤为:1)用户利用声音识别传感器采集语音,进行语音识别;2)识别结果通过串口(UART)向无线家庭网络的协调器(coordinator)发送交互指令;3)识别结果最终到达家用电器控制平台,平台按照识别结果内容发出控制指令。
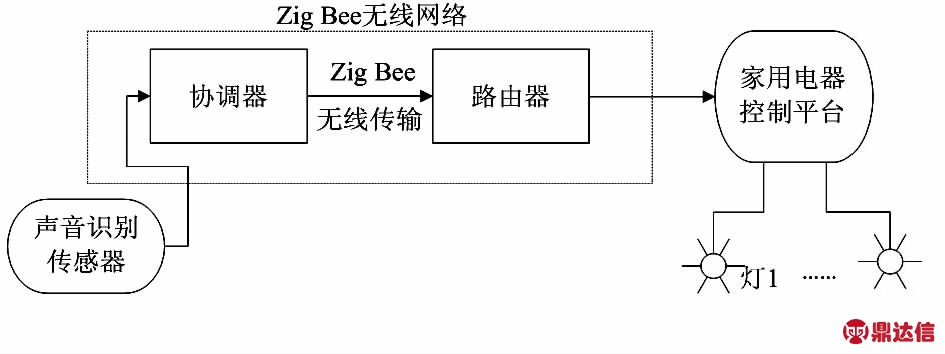
图5 智能家居系统体系结构
Fig 5 Architecture of smart home system
4.2 测试结果与分析
对于智能家居远程声控系统,最重要的就是在某些条件下保证系统的语音识别率、稳定性和响应时间。在安静的环境和较为嘈杂的环境下,本文分别对该系统进行了不同语音命令的识别率实验和系统稳定性实验。
针对同一模板,让特定人与非特定人分别对系统进行测试,对每条语音控制命令分别进行10次测试,每组的总实验次数为40次。表1是在安静环境下系统的语音识别率;表2是在一般噪音环境下系统的语音识别率。
表1 安静环境下系统的语音识别率
Tab 1 Rate of voice recognition in quiet environments
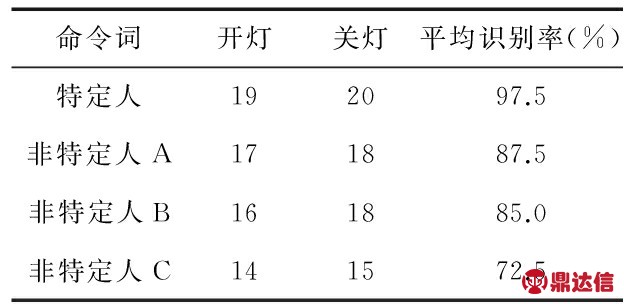
表2 一般噪音环境下系统的语音识别率
Tab 2 Rate of voice recognition in noise environments
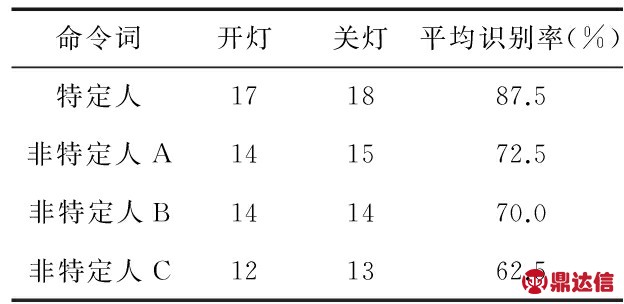
实验中的一般噪声指在正常生活情况下的声音环境,没有特别刺耳或尖锐的噪声,如火车或汽车喇叭声、人受惊吓时的尖叫声等。特定人指测试语音与训练语音为同一个人发出,训练模板为男生语音在安静环境下经训练而得到的;非特定人指测试语音与训练语音由不同的人发出,测试中非特定人A和非特定人B为男生,非特定人C为女生。
由表中数据可得,在安静环境下,特定人的识别率达到了97 %以上,非特定人A和B的识别率达到了85 %以上,完全可以满足智能家居的语音控制要求;因选用男声为模板,所以,对女声的识别率有所下降。训练样本时是在安静环境下进行的,因此,在噪声环境下相应的识别率也均有所下降,如表2所示,此时需要在噪声环境下重新训练语音样本,以提高系统识别时的抗噪能力。
在安静环境下系统的稳定性比较好,一般的语音命令发出1~2遍系统就可以做出正确的响应;而在噪声环境下,系统的稳定性有所下降,有的语音需要重复多遍才能被系统准确识别。
5 结束语
本文先从理论上研究了语音识别技术,并在此基础上根据需求设计了语音识别传感器。传感器采集语音信息并进行识别处理,并通过串口返回识别结果。本文利用声音识别传感器设计了一种智能家居远程声控测试系统,实验结果表明:声音识别传感器性能稳定,识别率高。
目前系统的语音识别功能,识别语句长度较短,数量有限,因此,可以进一步优化语音识别算法,改善硬件电路,增加语句长度,实现复杂语句的语音命令识别。
可进一步完善基于Zig Bee技术的智能家居系统,可以使用手机的3G功能远程传输命令,充分利用网络技术,使家庭内每一个家用电器都能通过无线设备形成独立网络,并和因特网相连,从而在真正意义上实现家居的网络化和智能化。


