
摘要:数显仪表的自动识别技术对提高其使用效率,拓展使用环境等方面具有重要意义。本文针对液晶数显仪表在图像采集过程中的笔画缺失(缺字),提出了一种数字自动识别算法。引入二维熵阈值对待识别的图像进行二值化分割,减小照度过低或照明不均匀的影响,同时采用多次分割、编码匹配的方式对缺字数字进行识别。经过多种仪表的识别实验,结果表明该方法满足仪表数字识别的速度和准确率要求,且对图像倾斜、缩放等均有较好的适应性。
关键词:数显仪表;数字识别;熵阈值;编码
0 引 言
液晶数显仪表在工业现场、计量实验室中有着广泛的应用。新式数显仪表大都有通讯数字输出,但仍有大量的仪表只能采用人工抄读的方式,效率低下,且在一些特殊的恶劣环境下,不便于人工操作;同时,液晶数显仪表有着较高的变化率(10 Hz左右),在数字变化的过程中,数字会有比较明显的拖尾或字符不全,在一些实时性要求较高的场合,采用人工判读的方式已经不能满足实际需要。因此,本文提出一种对液晶仪表缺字情况下的数字识别算法,能较好的实现其显示过程中的缺字字符识别,并对图像的倾斜、缩放、噪声干扰等影响有一定的适应性。
1 液晶数显仪表数字识别算法
数显仪表数字识别技术国内外已有较多相关技术进行研究,主要包扩基于统计的方法、基于结构的方法、基于BP神经网络的方法等[1-3]。数显仪表通常为8段码显示,有别于其它的OCR技术,考虑到识别的实时性,本文提出采用基于基线穿越的字符识别技术,并使用多次分割的方法对显示缺字时得出相应合理的判断;同时,针对负号和小数点,采用单独识别的方法,以减小错误概率。
整个识别过程包括图像获取与预处理,二值化分割,图像显示区域获取,单字符切割,单字符识别等过程。
1.1 图像预处理
图像预处理过程主要指图像的灰度化、二值化。
图像灰度化的方法一般有分量法,最大值法、平均值法和加权平均法等四种方法。本文选用加权平均法,它根据人眼对绿色的敏感度最高,对蓝色敏感度最低,以及其它的相关指标,按式(1)对彩色RGB图像进行加权平均,从而得到较合理的灰度图像。
式中: f ( i,j)为点 ( i, j)的灰度值; R ( i , j)、 G ( i,j)、 B ( i,j)分别表示点 (i , j)的红绿蓝分量。
灰度化后需要对图像进行阈值分割,得到二值化图像。由于实际工况的不同,图像的亮度和背景变化很大,不能采用固定阈值的二值化算法。为此本文选用具有较强自适应能力的二维最大熵阈值分割算法[4-5]。
若一幅图像的灰度级数为L,总的像素点数为 N ( m × n ),设 fi,j为图像中点灰度为i及其区域灰度均值为j的像素点数, pi,j为点灰度-区域灰度均值对 (i ,j)发生的概率,即:
则{ pi,j ,i,j = 1 ,2,…,L}是该图像关于点灰度-区域灰度均值的二维直方图,如图1所示。
图1中,沿对角线分布的A区和B区分别代表目标和背景,远离对角线的C区和D区代表边界和噪声,可在A区和B区上利用点灰度-区域灰度均值二维最大熵法确定最佳阈值,使代表目标和背景的信息量最大。
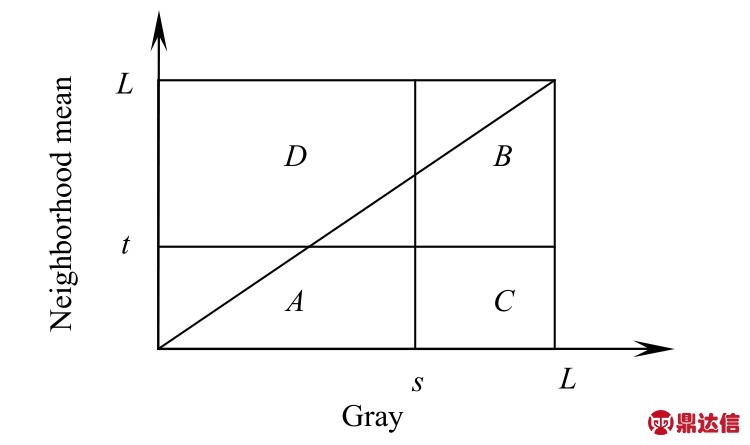
图1 点灰度-邻域均值直方图
Fig.1 Histogram of point gray - neighborhood mean
定义离散二维熵判别函数定义为
选取的最佳阈值向量 ( s * ,t*)满足:
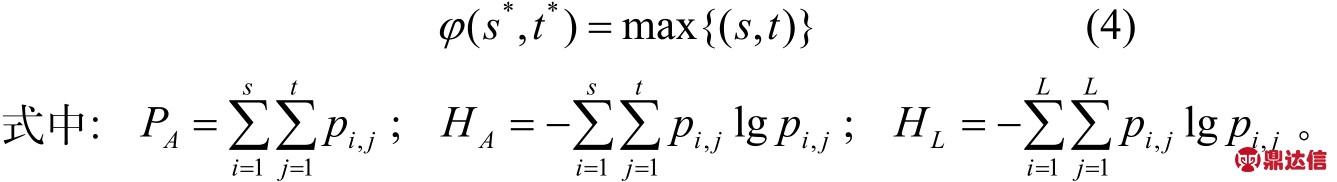
在上述二维阈值化方法中,对于每个 ( s, t )对,都要从头开始计算 PA ( s,t))和 HA ( s,t),计算复杂性为O ( L4),比较耗时。为了提高运算速度,可以采用递归的方式对二维最大熵计算进行优化,其主要递归公式为
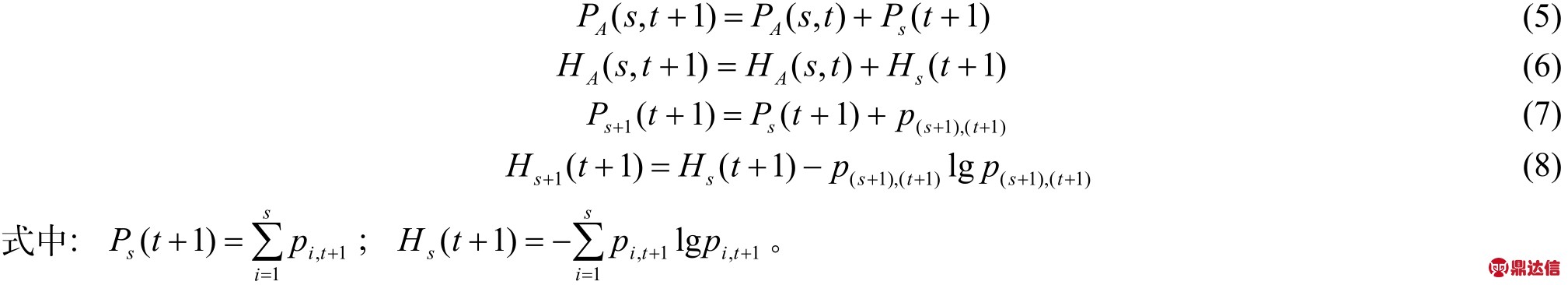
通过优化,递推算法可将计算的复杂性减至 O ( L2),大大减少了计算的复杂性,提高了计算速度。
图2,图3为原始图像与经过分割后的图像。

图2 原始图像
Fig.2 Original image
图3 分割后图像
Fig.3 Segmentation image
1.2 滤波处理
由于原始图像质量较差,分割后需采用多种手段进行滤波处理。
首先按连通区域大小去除噪声,其过程为
1) 依次遍历每一个像素点;
2) 如该点没有被访问过并且是前景色(黑色)则作为一个种子点,标记该点访问过;
3) 依次遍历它的一阶邻域内的4个像素点(四邻域),递归调用算法第2)步。
采用以上方法可得到图像的所有连通区域,将面积大于阈值的连通区域填充为背景色(白色),可得到一个去除了较大噪声的图像,如图4所示。该过程虽有递归,但是其执行过程实际上只遍历了图像每个像素点一遍,保证了运算速度。
图4 连通域滤波分割后图像
Fig.4 Image of connected domain filtering

图5 中值滤波后图像
Fig.5 Image of median filter

图6 膨胀后图像
Fig.6 Image of dilation
在连通域滤波之后,再使用大小为3×3窗口的中值滤波对图像进行平滑处理,其滤波后结果如图5所示。中值滤波后,数字边缘清晰,但其中存在一些断点。为提高数字区域的连通性,增大线宽度,对二值图像实行形态学的膨胀操作(采用2×2大小的窗口)。其处理结果如图6所示。
1.3 数字分割
经过二值化与滤波等处理后,采用投影法即可确定数字显示区域[6]。确定区域后,传统分割数字的方法如投影、空洞法等等,考虑到图像倾斜、噪声及背景等因素的影响,上述方法经常产生误判,为此,本文选用基于最小欧式距离的方法分割数字。
虽然图像经过了膨胀的处理,但仍有部分数字区域不连通。在图像滤波处理的过程中已计算出图像中的连通区域,并记录每个连通区域所有边缘点的坐标。如果一个点的所有一阶邻域的点都是前景色(黑色),则该点不是边缘点,否则该点为边缘点。通过连通区域最小间隔的计算可以判断出两个区域是否为同一个数字的一部分,或者属于两个不同的数字,此即连通区域的分组。
两个连通区域之间距离的计算方法为:遍历两个连通区域的所有边缘点,计算两两之间的距离,求出一个最小的距离即两个连通区域之间的距离。距离按照欧几里得距离计算:设两个点坐标分别为 a1 ( x 1,y1),a2 ( x 2,y2),两点之间的欧氏距离记作 d ( a 1,a2),则:
设两个连通区域 S1和 S2的距离为
如果两个连通区域接近且小于阈值时,则认为属于同一个数字,否则是不同数字。分割后的数字图像如图7所示。
图7 分割后的数字图像
Fig.7 Digital image of segmentation
1.4 缺字字符识别
数字分割结束需要对数字进行识别。数字识别的方法有很多,如基于模版匹配的方法、基于神经网络的方法等。考虑到待识别数字均为数码管形式显示,采用计算效率较高的基于基线穿越的字符识别方法[7];缺字识别的主要思想是采用多次分割,编码匹配的方式。
数显仪表的数字形式为7段数码管字体,如图8所示。使用5根穿越基线穿越分割后的数字,依据基线与待识别数字笔画的相交情况,对照字符编码表(如表1所示)判别图像所对应的正确数字。
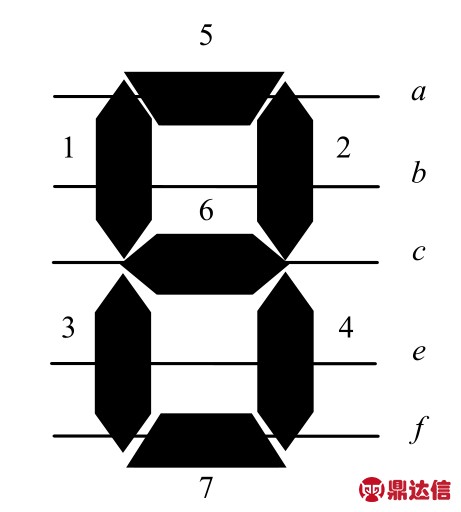
图8 字符笔画的编码
Fig.8 Encoding of character strokes
表1 字符编码表
Table 1 Character encoding table
采集到的数字图像由于液晶的拖尾特性,以及CCD曝光时间与数字变化周期不匹配等原因造成获取的字符不完整,如图9即为其中一个实例。
对于缺字情况,可采用多次分割,最近似编码匹配的方式,其具体算法如下:
1) 从二值化的图像显示区域中分割出数字,调用基于基线穿越的数码管数字识别算法(以下简称为基础算法),得到一个编码结果,如与表1中某个编码完全一致,则算法停机;
2) 如与表1中任何一个编码都不完全一致,则从原图副本(未二值化的图像)中分割出字符后,再进行二值化处理,调用基础算法,得到一个编码结果;
3) 将步骤2)得到的编码结果与表1中的10种编码相比较,排除没有对应笔画的编码;4) 将步骤1)得到的编码结果与表1中的10种编码相比较,排除没有对应笔画的模板;5) 从剩余的编码中选出与待匹配编码最相似的作为结果,算法停机;
6) 如没有剩余编码,从所有编码中寻找与待匹配编码最相似的作为结果,算法停机。
针对图9中的数字,图10,图11分别为采用基础算法和缺字识别算法后得到的二值化图像。从图中可看出未采用半字分割时,表1中没有对应的编码,不能给出正确的结果;而采用缺字识别算法后的识别结果为29.5,与人眼观测结果一致,且与实际情况比对后,也证明此结果的正确性。

图9 缺字图像原始图像
Fig.9 Original image of stroke missing

图10 基础算法分割
Fig.10 Segmentation of basic method
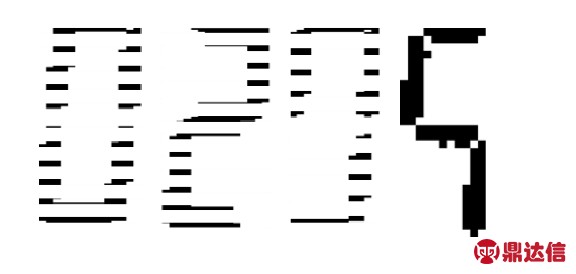
图11 缺字分割
Fig.11 Segmentation of stroke missing
除采用上述方法外,在短时间内,由于数显仪表显示的数据变化方向相对固定,因此可利用当前图像的前后数帧图像来进行综合判断,结合模糊理论,可进一步提高识别的正确率。
1.5 小数点与负号的识别
数字识别中,小数点和负号与0~9数字在形态上有较大不同,需单独识别。小数点和负号的识别与数字的识别同等重要,其识别错误造成的误差要大于单纯数字识别误差。
小数点的识别相对较简单。当识别出数字后,小数点在图像中的位置也确定了,且小数点出现的位置范围固定,在数字区域下边缘的区域附近。如图12框选的区域,在这个区域内查找类似小数点的连通区域即可。算法遍历这些连通区域,通过连通区域面积大小、长宽比例和高度位置等信息先排除不可能是小数点的区域,再从剩下的区域中选择面积最大的作为小数点位置,插入到数值当中。
采用和小数点的识别类似的方法思路可识别出负号,不再赘述。

图12 小数点的位置区域
Fig.12 Position of decimal point
2 实 验
为验证以上算法有效性,设计了相关实验进行验证。实验硬件设备为:相机选用大恒图像,分辨率为1 600×1 038;镜头选用日本Computar 50/1.8定焦镜头;待测仪表为优利德56和胜利70F,其典型缺字图像如图13,图14。
将相机采集帧频设为20帧/秒,针对两种仪表,在不同情况下,分别采集1 000帧图像,从中筛选出缺字的图像进行识别。胜利70F的实验结果如表2所示。

图13 胜利70F图像
Fig.13 Image of 70F
图14 优利德56图像
Fig.14 Image of UNIT 56
表2 各种情况下的识别实验
Table 2 Recognition experiments

从表中可以看出,图像缩放对识别率的影响不大;图像倾斜后,由于识别时采用穿越基线的方式,倾斜角度过大,对识别率会产生一定影响;同时,如果联系当前图像上下文显示时,可显著提高识别率。
优利德56比胜利70F的表盘显示简单,经实验表明,二者的识别率相近。
3 结 论
本文针对数显仪表在采集过程中,数字图像出现的缺字情况进行了研究。为适应无照明或者照明不均匀的情况,选择二维熵阈值对图像进行二值化分割;使用连通域滤波、中值滤波、膨胀等手段去除数字之外的干扰;最后,选择基于基线穿越的方式来确定字符编码,查表后得出识别后的结果。通过对两种数显仪表的大量实验表明,本文的方法满足数显式仪表实时监测的需要。


