
摘 要:针对目前智能手机识别人体运动状态种类少、准确率低的问题,提出一种利用加速度传感器和重力传感器分层识别人体运动状态的方案。首先,利用加速度和重力加速度的关系计算出与手机方向无关的惯性坐标系下的线性加速度;其次,根据人体运动频率的变化范围和线性加速度矢量来确定脚步的波峰和波谷位置;最后,提取线性加速度在时域上的特征向量,使用层次支持向量机方法分层识别人体运动状态。实验结果表明,该方法能有效识别人体6种日常运动状态,准确率达到93.37%。
关键词:运动状态识别;层次支持向量机;智能手机传感器;时域特征
1 引言
随着智能手机的不断发展,智能手机中嵌入了各式各样的传感器,如重力传感器、加速度传感器和陀螺仪等,使手机的功能变得越来越强大。利用智能手机中的传感器对人体运动状态进行识别,正在成为相关领域的研究热点。该类研究是通过手机中的传感器采集与人体活动相关的数据来识别手机携带者的运动状态。
在人体运动状态识别方面,智能手机与其他可穿戴设备相比具有不受外部环境限制、不需要额外增加设备、不妨碍日常生活等优点。智能手机除了用于健康监控、智能家居、智能监控外,还可以在病人监护、运动评估和交通行为监测等方面挖掘其应用价值。
现有的研究在人体运动状态识别类型和识别精度方面均取得了不错的效果,但是只有少数研究者考虑了智能手机放置位置[1-3]对人体运动状态识别的影响。运动传感器对身体位置的敏感性是智能手机进行运动状态识别的挑战之一。在大多数研究中,均将手机放置的位置保持不变,因为位置的变化可能导致运动状态识别性能的下降。
有些传感器对方向的变化很敏感,例如加速度传感器和陀螺仪,手机放置的方向会影响运动状态识别效果[4-5]。由于缺乏方向独立性,用户需要将手机置于特定的方向,限制了用户使用智能手机的方式。因此,为了方便用户使用,运动状态识别方案应该与手机方向无关,手机可以在任意方向识别人体的运动状态。方向无关性主要通过以下2种方法实现:1) 使用与方向无关的特征向量,如使用加速度矢量和而不是其各自的三轴值来计算特征向量,因为加速度矢量和的大小对于方向的变化不敏感,但这种方法对运动状态的识别有一定的影响;2) 使用信号转换,将智能手机的坐标系转换成惯性坐标系来抵消方位变化[6],与方法1)相比,如果能够实现准确转换,将有利于提高人体运动状态识别的准确率。
在运动状态识别中特征向量的提取起着至关重要的作用。从传感器数据中提取的特征向量主要有时域特征向量和频域特征向量2类。提取频域特征向量时需要进行傅里叶变换[7],计算负载较大。数据采集时,由于受环境的干扰,采集到的数据存在抖动和噪声脉冲,影响特征向量的最大值或最小值。
针对以上问题,本文从手机携带方式、与手机方向的无关性和时域特征向量3个方面进行研究,使用层次支持向量机(H-SVM,hierarchical support vector machine)方法对日常生活中具有代表性的运动状态进行识别,为生活健康提供监控。根据文献[8]可知,人的心脏代谢的健康与中等运动强度有一定的关系。因此,本文将静止(站立/静坐)、行走、跑步、上楼、下楼和骑行6种日常运动状态作为研究对象,具有较高的研究价值。本文选择胸口、上臂、裤前袋、裤后袋和腰部这5个日常生活中人们常放置手机的部位作为手机携带方式。根据线性加速度特征向量的取值和对人体运动的先验知识,先对6种运动状态进行分层,再采用H-SVM方法对运动状态进行识别。
本文的主要贡献如下。
1) 根据人体运动状态的特征,设计并实现了一个分层识别人体运动状态系统。当用户使用不同的手机携带方式并且在手机随机摆放的情况下,系统能有效识别出日常生活中用户的6种运动状态。
2) 提出了一种手机坐标系与惯性坐标系的实时转换算法。通过手机坐标系下加速度和重力加速度之间的关系,精确计算惯性坐标系下人体运动的线性加速度,避免了只使用线性加速度转换导致的转换精度不高的问题[9-12],转换后的运动数据真实反映了人体的运动状态,而且与手机放置方向无关,提高了用户使用手机的自由度。
3) 设计了寻找惯性坐标系下线性加速度的最大波峰点和最小波谷点的脚步识别算法。利用人体日常运动频率为1~3 Hz[13]的特性,提高了脚步识别算法的计步准确率,有效计算时间窗口内脚步的最大值均值和最小值均值,提高了运动状态识别的准确率。
2 研究背景及相关工作
基于传感器的运动状态识别,国内外学者已经有了较长时间的研究。文献[14]把单个加速度传感器固定在人体的骨盆附近,对人体站立、跑步和刷牙等9种运动状态进行识别,并取得了较好的效果。文献[15]在室内使用多个传感器组建传感器网络,识别人体在室内的多种活动。文献[16]提出了基于单个加速度传感器系统,可以识别出5种运动状态,识别的准确率达到94%。文献[17]通过可穿戴的多个传感器设备,对人体的运动状态进行实时识别,并根据运动状态来计算人体运动时的能量消耗。文献[18]提出一种分级预测模型对人体静态、动态和过渡活动进行分类,能识别人体的15种活动,并取得了令人满意的识别精度。
以上研究面临的一个共同问题就是需要独立的设备并且佩戴在身体的某个特定部位,这样会增加成本并给行动带来不便,另外,还需要对多个传感器数据进行分析整合,带来较大的计算开销,实时性较差,很难达到真正意义上的普及。
文献[19]使用Android设备识别出高精度的活动,但是识别精度与Android设备放置的方向有关。文献[20]在智能手机中完成数据采集、特征向量提取和分类识别,识别步行、跑步、骑车、开车、坐/站5种日常活动,但是采集数据时手机需放在固定的位置,并且使用了42个特征向量,增加了手机的负载。文献[21]提出智能手机采集腰部数据检测摔倒模型,但手机必须固定在腰部位置。文献[22]采用线性加速度传感器和陀螺仪对方向进行校正,使识别的准确率提升到93%,但与文献[21]相同,采样时手机固定在某一特定的位置。文献[23]对加速度传感器数据进行离散小波变换,将每层高低频的能量作为运动特征,使用朴素贝叶斯和多层感知器的分类方法对7种运动(静止、行走、跳、冲刺跑、击球、截球、运球)分类,识别的准确率最高达到87%,同样,该方法需将传感器固定于身体特定位置才能进行识别,降低了灵活性。文献[24]研究了数据采集与传感器位置的无关性,但识别精度不及固定传感器的方法。文献[25]将动作传感器在时序前后采集的数据作为上下文来改进用户活动识别,提高了动作识别的精度,但是实验的数据来自固定于胸前的传感器。文献[26]对比智能手机中三轴加速度传感器和陀螺仪在单独使用和联合使用情况下对走、上楼、下楼、坐、站和躺6种状态的识别,提出了一种新的特征选择方法,构造了一个具有较好泛化能力的在线活动识别器,降低了智能手机的功耗,但是没有对跑步和骑行运动状态进行研究,同时选择了运动数据在频域上的特征向量,增加了手机负载。文献[27]联合使用手机内置传感器和手腕运动传感器,得到更多的上下文信息,识别了13种生活中复杂的运动,但是系统增加了额外的传感器。文献[28]使用线性加速度传感器的标准差作为特征向量识别站立、行走和跑步3种运动状态,准确率达到98%以上,但是识别的运动状态较少。文献[29]采用传感器在时域、频域和时频域上的特征向量,用K近邻算法、随机森林算法和支持向量机算法对手机在不同携带方式下不同的运动状态进行分析。文献[30]把运动状态分为上楼、下楼、走路、跑步、静坐和站立6类,在验证系统的识别效果时只用了3组用户的实验数据,而且没明确手机的携带方式,同时缺少了骑行这一常见的运动。
针对以上问题,本文采用智能手机中的线性加速度和重力加速度来识别生活中常见的6种运动状态。
3 数据采集及处理
本节使用手机加速度传感器和重力传感器采集人体运动状态数据,然后对数据进行校准、平滑、分割、与手机方向无关性处理。图1为人体运动状态识别系统的结构。
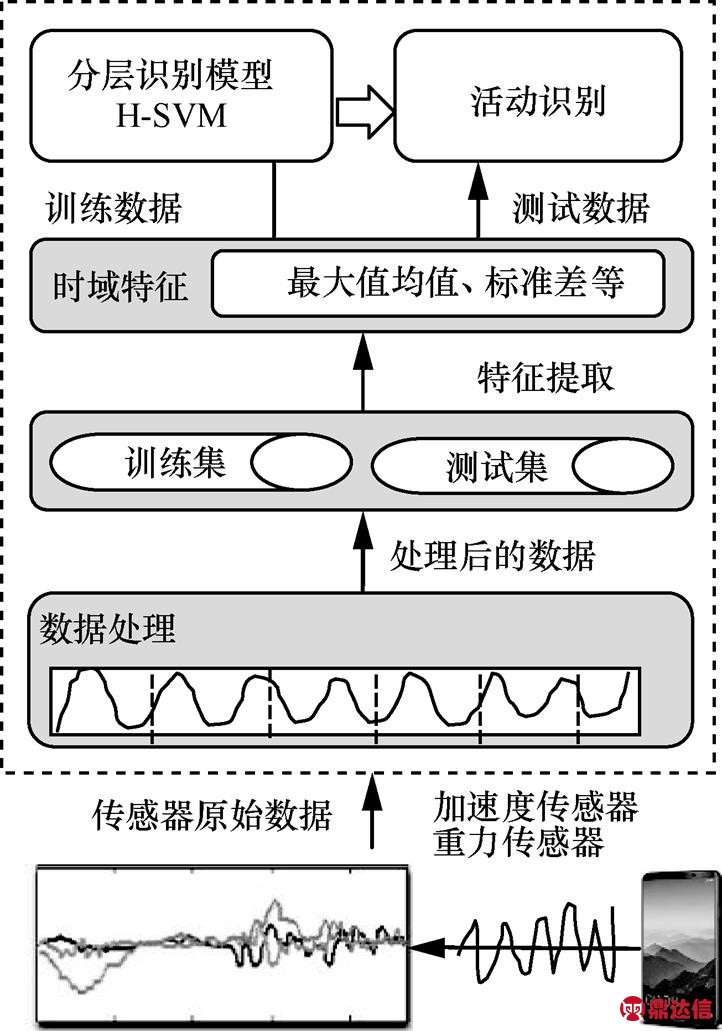
图1 人体运动状态识别系统的结构
3.1 数据采集
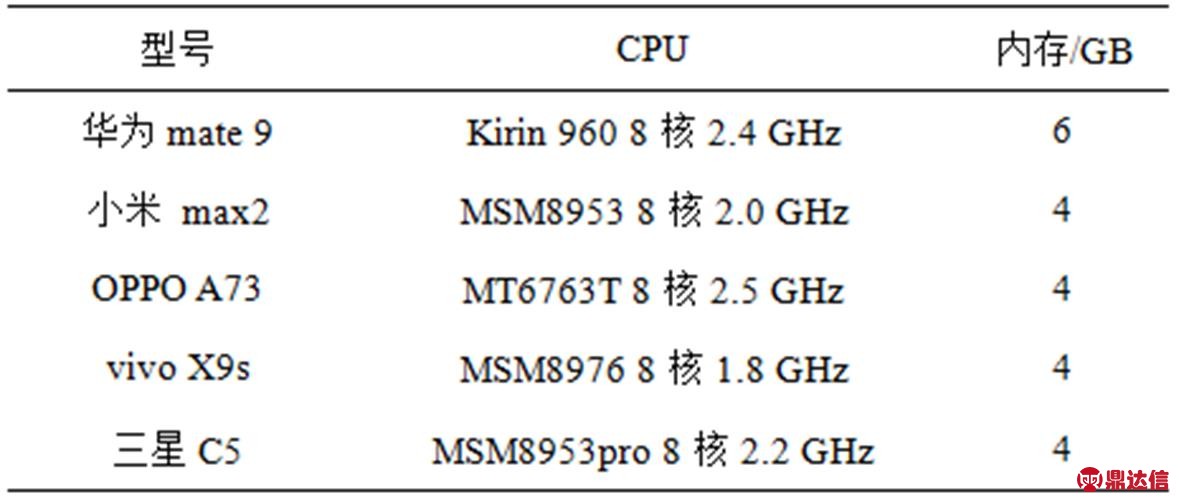
本文在Android设备上开发了一个数据采集应用程序,应用程序可以安装在Android 4.0以上的设备上。在程序运行时,每隔30 ms读取加速度传感器和重力传感器三轴数据,然后将其以明文方式存储在手机本地test文件夹中。在测试阶段,将原始数据传输到后端服务器。实验使用5种不同型号的智能手机进行数据采集,如表1所示。
表1 实验中使用手机型号
本实验邀请了在校的20位大学生作为实验者,其中男性15名,女性5名,年龄分布在18~22岁,体重45~80 kg,身高155~180 cm。数据采集时,将5部手机分别放置在实验者的胸口、上臂、裤前袋、裤后袋和腰部这5个部位。为使每部手机都能采集到不同部位的运动状态,每位实验者在同一种运动状态中进行5轮数据采集,每完成一轮数据采集后,循环更换手机位置,共收集每位实验者的30轮数据(5轮采集,6种运动状态)。
在实验设置中,上楼和下楼运动状态是在8层教学楼的楼梯上完成的,行走和骑行运动状态是在学校的运动场完成的,静止状态是在教室内完成的。为了确保每个实验的运动数据接近正常生活,本文没有控制运动的速度和手机放置的方向,每2轮实验之间让实验者休息并改变5部手机的携带位置和方向。每轮数据采集的持续时间不少于2 min,共收集6 000 min的数据进行验证。
3.2 数据校准
由于传感器在制造和安装过程中存在一定的偏差,影响传感器数据的准确获取[31]。为了尽可能地减少传感器获取数据的固有偏差,保证数据的准确性和不同加速度传感器之间数据的一致性,国内外学者针对三轴加速度传感器的校准进行了研究。文献[32]使用最大似然求解方法,对加速度传感器进行自动校正,提高了加速度传感器的校准精度。文献[33]先对原始加速度传感器数据进行预处理,再使用遗传算法最优化求解校准参数,简化了传统标定方法步骤。文献[34]利用当地重力加速度g作为标定基准,使用线性最小二乘法对加速度传感器进行校准。文献[35]使用高斯−牛顿迭代法对加速度传感器进行校准。本文针对加速度传感器和重力加速度传感器X、Y、Z轴上的输出的数据,使用缩放矩阵S和偏置矩阵B校准加速度数据矢量[x, y, z]T,如式(1)所示。其中,S为3×3的缩放矩阵,s11、s22、s33为加速度传感器的标度系数,sij(i≠j)为加速传感器的安装误差系数,矩阵B校正加速度传感器的零位偏差。
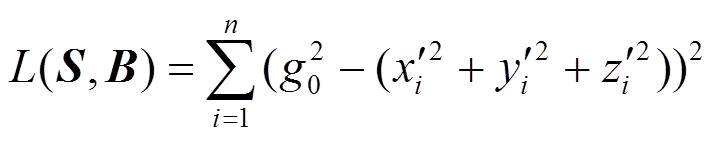 (1)
(1)静止时,加速度传感器数据和重力传感器数据三轴输出值x、y、z的平方和等于当地重力加速度的平方,如式(2)所示,对应的线性加速度矢量和为0 m/s2,但是手机获取的线性加速度输出并不总是满足这一条件。
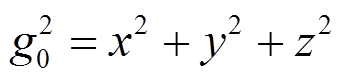 (2)
(2)
通过采集静止状态下加速度传感器和重力加速度传感器输出值,利用差分进化的混合粒子群优化(DE-PSO, differential evolution of particle swarm optimization)算法求解非线性方程组[36],构造目标函数如式(3)所示。
(3)其中,i为静止状态下测试的数据数量,g0为当地的重力加速度,通过最小化目标函数即可得到S和B。静止状态下加速度传感器数据和重力传感器数据如图2所示,静止状态下加速度数据校准前后对比如图3所示,经过校准后静止状态下加速度数据接近9.81 m/s2,满足对数据进一步处理的需求。与高斯–牛顿迭代法相比,DE-PSO算法运行速度较快,仿真时间较短,误差较小,适合智能手机中加速度传感器数据的校准。
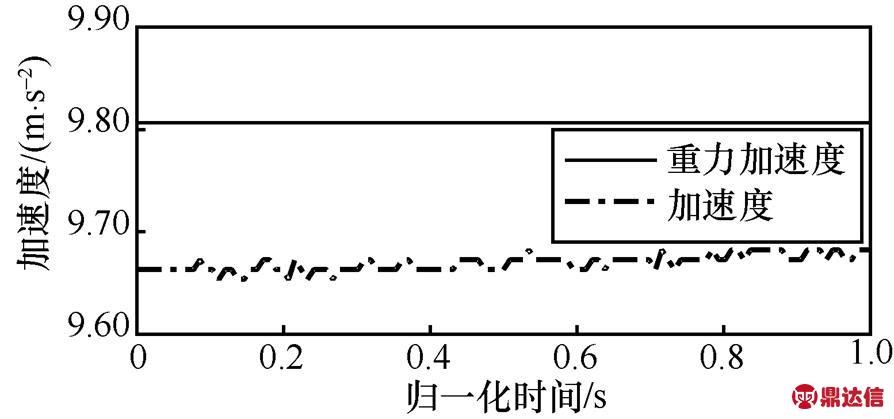
图2 静止状态下加速度传感器数据和重力传感器数据
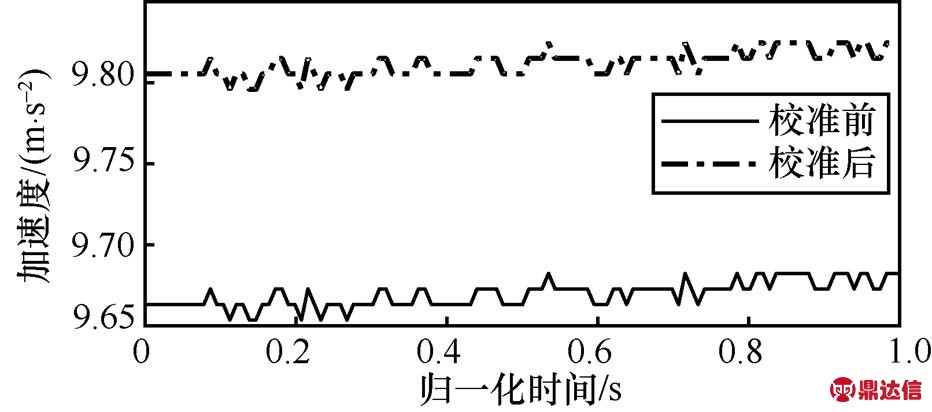
图3 手机静止状态下加速度传感器数据校准前后对比
3.3 数据滤波
经过校准处理后,线性加速度矢量和应能够真实地体现人体运动状态。本文研究的运动状态除静止状态外,其他的运动状态都是周期运动。以行走为例,从一侧脚跟落地开始到其再次落地构成了一个步态周期,双脚交叉依次进行,由此引起手机加速度传感器数据变化应该呈现类似于正弦波型,如图4所示。图5展示了用户携带手机运动时,某一段时间内加速度传感器数据变化情况,与理想状态波形有较大的差别。由于传感器数据的不稳定性,即使手机处于静止状态,其数据也普遍存在抖动现象,有时候甚至会存在脉冲。本文采取滑动加权均值办法对传感器数据抖动和脉冲噪声进行处理,降低此类噪声对传感器数据的影响。滑动加权均值办法是在一个包含2k+1个数据点的窗口内,用窗口内的几个数据点的权重比之和代表该值的大小,实现数据的平滑处理,如式(4)所示。
图4 理想状态下步伐的加速度数据
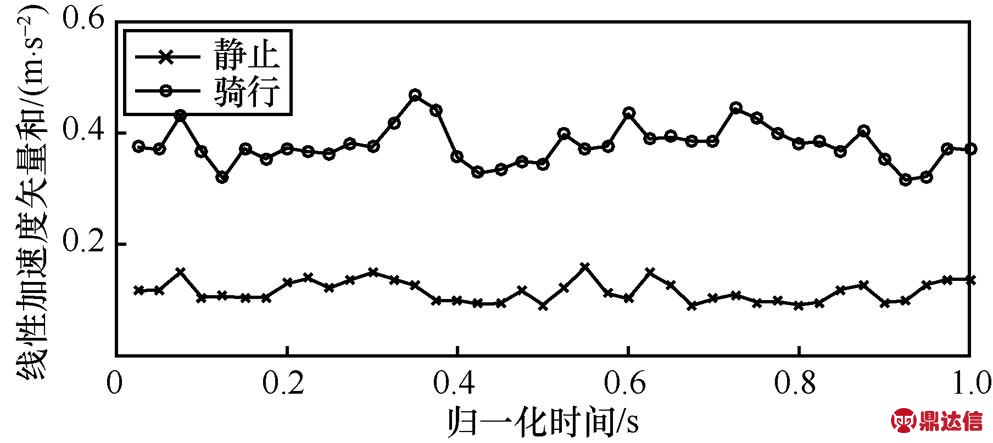
图5 加速度传感器的原始数据
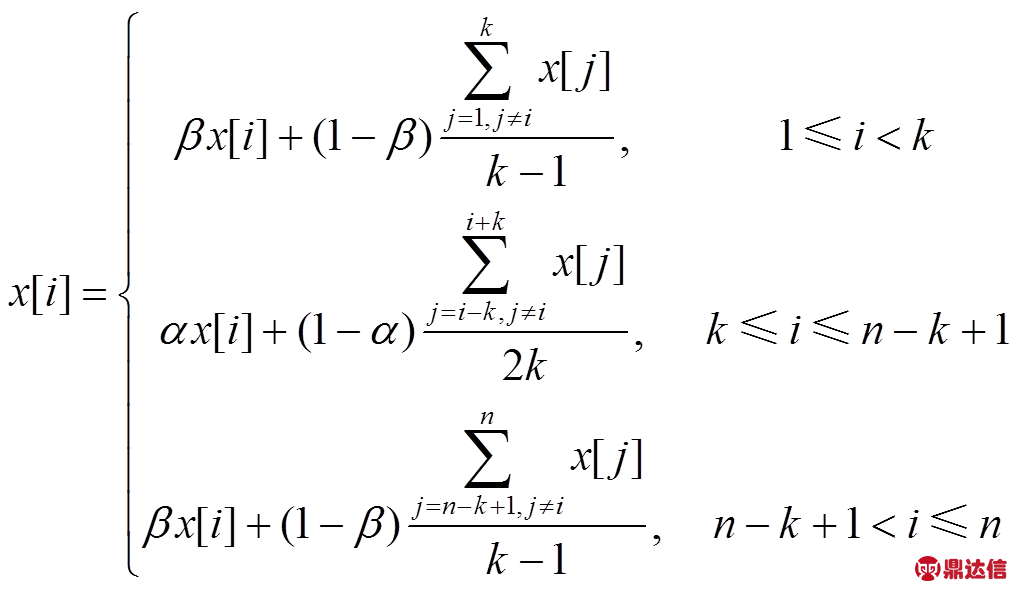 (4)
(4)其中,n为窗口中数据的长度,α、β为权重。滑动加权均值滤波可以对数据抖动进行有效的处理,平滑效果与窗口2k+1和权重α的取值都有关,在α一定的情况下,2k+1越大,平滑效果越好,失真的程度也就越高,而窗口起始和结束的k个数据的平滑与β的取值有关。当α=0.2,β=0.8时,k分别取3、7和11时平滑的效果如图6所示;当k=7,β=0.8时,α分别取0.2、0.6和0.9时平滑的效果如图7所示。通过多次实验并与卡尔曼滤波比较,选取α=0.2,β=0.8,k=7能够得到较好的平滑效果,如图8所示。与卡尔曼滤波相比,这种滤波方法的降噪性能不够好,但计算过程简单快捷,这意味着智能手机的计算负载更轻。与图5相比,采集到的原始数据经过平滑处理之后,数据质量和平滑度都有了明显的提高。
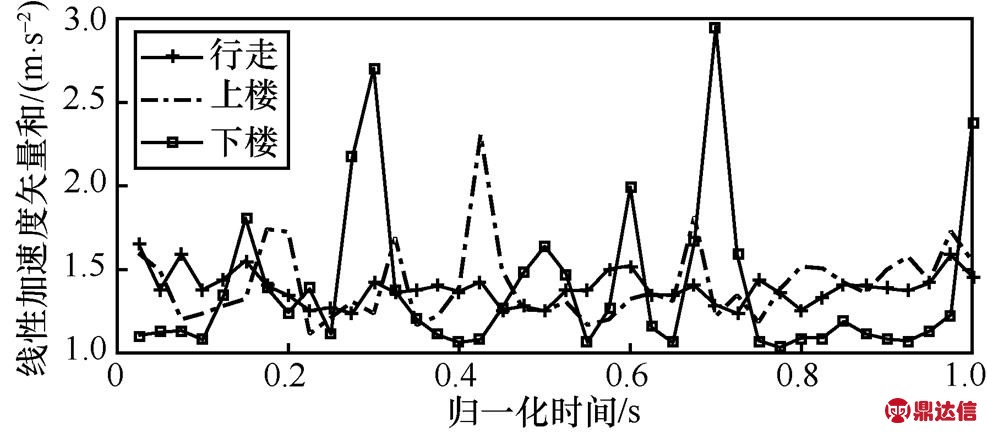
图6 k取不同值时加权滤波
图7 α取不同值时加权滤波
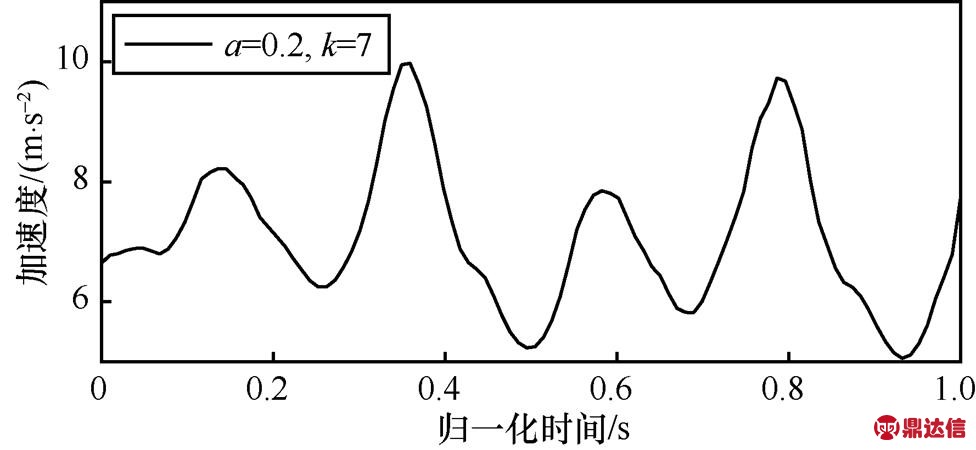
图8 过滤后的加速度数据
3.4 数据分割
经过校准和滤波处理后的传感器时序数据虽然已接近理想状态,但是数据序列较长。如果对时序数据中每个采样点都进行特征向量计算,虽然单次计算的时间最短,但是随着检测次数的增多,会导致总的检测时间过长,严重影响系统的实时性,所以必须对数据进行分割处理。数据分割是保证实时性和准确性的基础。
本文采取滑动窗口机制,将待处理的长时序数据序列分割成若干个短的时序数据序列,然后对分割后的若干个短的数据序列进行相应的特征向量计算。数据序列的分割会带来分割窗口边缘的关键数据受损,影响数据的准确性。本文采取重合窗口与动态窗口相结合的方法,即带有50%重合的滑动窗口策略,如图9所示。滑动窗口T设为1.5 s[37-38],用窗口内数据的均值代替滑动窗口的值,然后利用各个滑动窗口的特征值向量进行运动状态的识别和划分。
3.5 与手机方向无关性处理
在数据采集过程中,本文方案不要求手机按照某一方向携带。手机的方向不同,加速度传感器三轴分别受到重力的影响就不同。文献[9]假设某段时间内手机方向不发生改变,用此段时间内加速度的均值和加速度的关系,计算加速度传感器的方向,这样就可以获得线性加速度在铅垂面和水平面上的加速度分量。在实际应用中,手机可能随时改变方向,用加速度的均值计算加速度传感器方向存在较大误差,影响线性加速度在水平面和铅垂面上分量的准确性。本文采用加速度传感器数据和重力传感器数据计算人体运动在水平面和铅垂面上的线性加速度,算法的时间复杂度为O(1),如算法1所示。
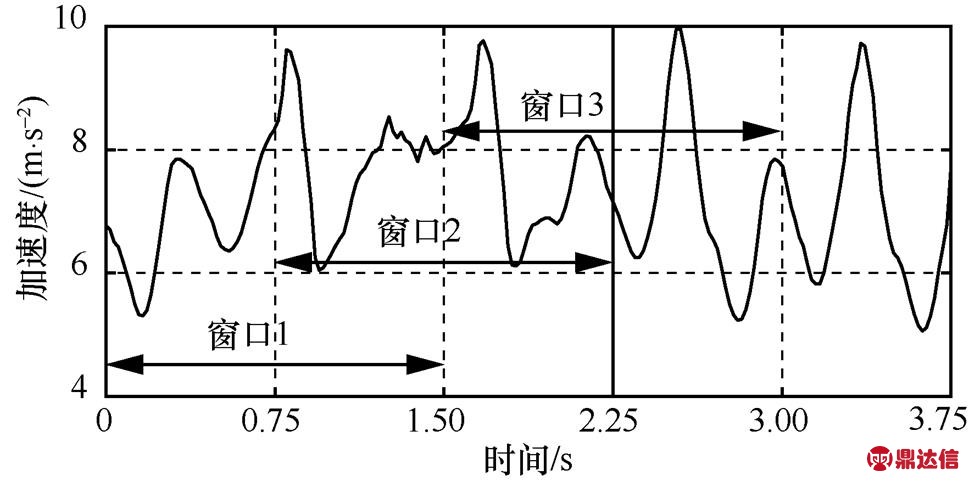
图9 滑动窗口示意
算法1 坐标转换算法
输入 加速度传感器数据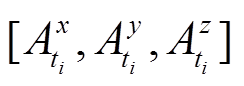 和重力传感器数据
和重力传感器数据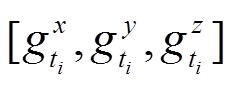
输出 惯性坐标系下线性加速度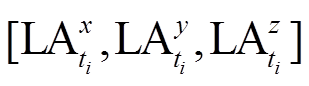
Step1 初始化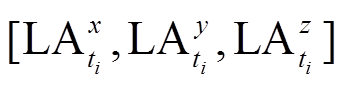
Step2 计算手机坐标系下线性加速度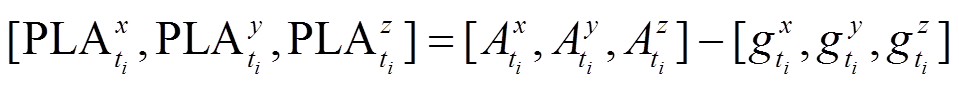 (5)
(5)
Step3 计算重力加速度矢量和
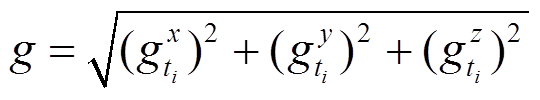 (6)
(6)Step4 计算惯性坐标系下线性加速度
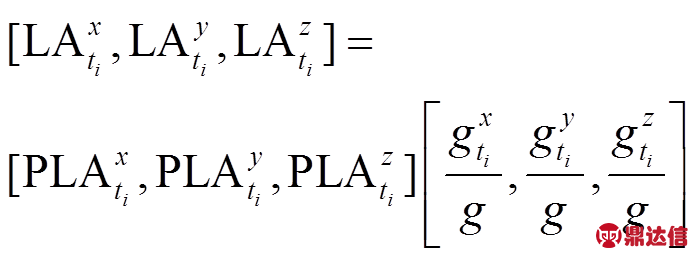 (7)
(7)
为得到线性加速度的整体变化特征,可通过式(2)计算线性加速度的矢量和。经过算法1处理后的线性加速度是惯性坐标系下的线性加速度,与手机的放置方向无关,并且真实地反映了人体的运动状态。
4 特征向量选择及运动状态分析
特征向量选择是人体运动状态识别的重要环节,其目的是在原始数据中选择有效的特征变量,获得待研究对象的本质属性,从而准确描述待研究的对象。特征向量选择直接影响到整个模型的识别性能。首先,根据ReliefF算法[39]选择有效的特征变量;然后,利用脚步识别算法计算脚步的波峰和波谷值;最后,根据脚步的波峰和波谷值计算相应的特征向量值。
4.1 特征向量选择
从已有的研究成果看,目前,应用最广泛的特征主要包括2类,即时域特征向量和频域特征向量。时域特征向量计算复杂度相比频域特征向量低,在人体行为识别的应用中有较理想的体现。时域上的特征向量包括最大值、最小值、中位数、平均值、标准差、方差、偏度、峰度、直方图信息、均方根、自回归系数、互相关系数、过零率、上四分位数和下四分位数等。
本文方案只使用时域上的特征向量,有效地降低了算法的复杂度。根据ReliefF算法计算特征向量的权重,采用惯性坐标系下线性加速度在水平方向、垂直方向和矢量和方向的最大值均值、最小值均值、平均值、标准差、最大值均方根、四分位差、偏度和峰度共24个时域特征向量。
计算最大值均值和最小值均值时,需要用脚步识别算法来确定脚步的波峰和波谷位置,然后计算脚步在不同的方向上的波峰和波谷值。最大(小)值均值是指时间窗口内脚步波峰(谷)的平均值。在计算最大(小)值均值时,需要获取时间窗口内运动的步数。文献[11]采用固定时间阈值办法实现正常运动状态的步数统计,运动状态变化较大会导致计步精度下降[40]。本文提出了寻找最大波峰点和最小波谷点的脚步识别算法,如算法2所示。首先,寻找时间窗口内线性加速度的最大波峰点和最小波谷点,即时间窗口内某一脚步的波峰点和某一脚步的波谷点,然后分别以此最大波峰点和最小波谷点为起点,在距此波峰或波谷前后0.33~1 s范围内查找最大波峰点或最小波谷点,此点即为下一脚步或前一脚步的波峰或波谷。以新的波峰或波谷为起点,继续寻找下一脚步或前一脚步的波峰点或波谷点,直到时间窗口内所有脚步的波峰或波谷都被找到。算法的时间复杂度为T(n)=n+2n=O(n)。
算法2 脚步识别算法
输入 线性加速度矢量和Data及相应的时间点time
输出 步数stepNum、脚步波峰值stepPeak、脚步波谷值stepTrough 和脚步峰谷值stepData
Step1 初始化stepNum、stepPeak和stepTrough
Step2 遍历窗口内所有数据点,找出最大波峰点maxpoint和最小波谷点minpoint,更新stepNum、stepPeak和stepTrough
Step3 在时间窗口内,以maxpoint为起点,在距离maxpoint 0.33~1 s时间范围内,查找下一个脚步波峰点,更新stepNum和stepPeak,以新的波峰为起点继续查找下一个脚步的波峰点,直到窗口内所有的脚步波峰点被查找到
Step4 在时间窗口内,以minpoint为起点,在距离minpoint 0.33~1s时间范围内,查找下一个脚步波谷点,更新stepNum和stepTrough,以新的波谷为起点继续查找下一个脚步的波谷点,直到窗口内所有的脚步波谷点被查找到
Step5 stepNum =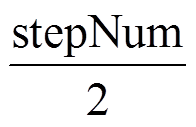
stepData= stepPeak ∪stepTrough
4.2 运动状态分析
通过前期数据采集和处理,可以得到每一种运动状态的惯性坐标系下线性加速度的24个时域特征向量。本文对惯性坐标系下线性加速度矢量和的特征向量做如下分析。
为区分不同的运动状态,绘制出6种运动状态的最大值均值图,如图10所示。由图10可知,跑步的最大值均值最大,静止和骑行运动的最大值均值最小,行走、上楼和下楼的值在以上两者之间。同样地,绘制出6种运动状态的最小值均值、平均值和标准差的特征向量图,如图11~图13所示。可以看出,这3种特征向量与最大值均值有相似的变化规律。通过以上分析可以把运动状态分成3类,即跑步为一类,行走、上楼和下楼为一类,而静止和骑行为一类。
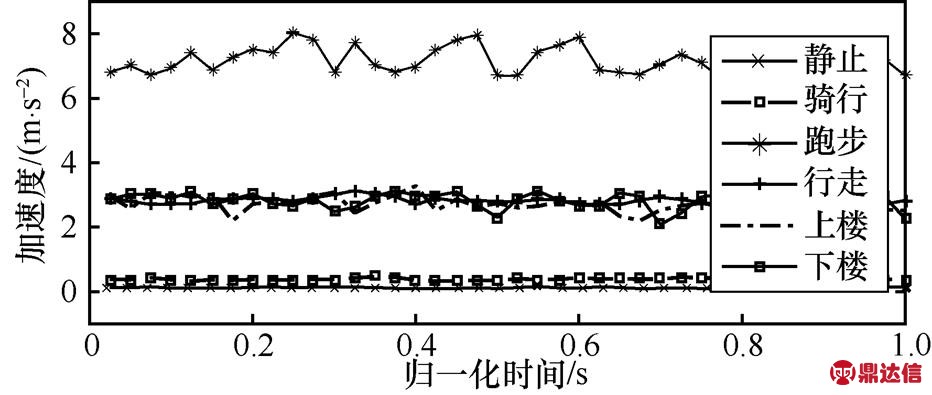
图10 6种运动状态下的最大值均值
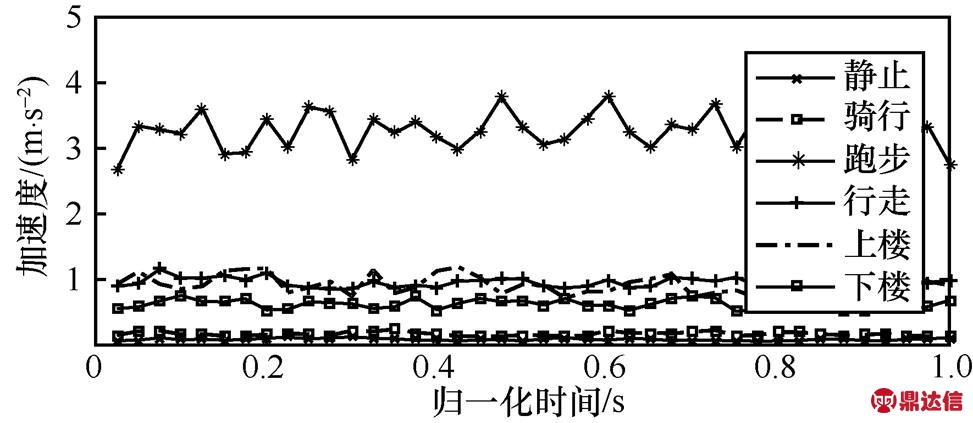
图11 6种运动状态下的最小值均值
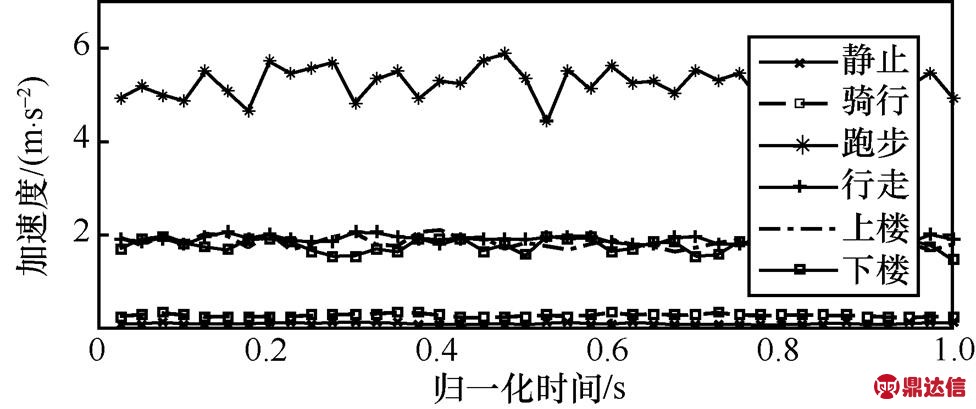
图12 6种运动状态下的平均值
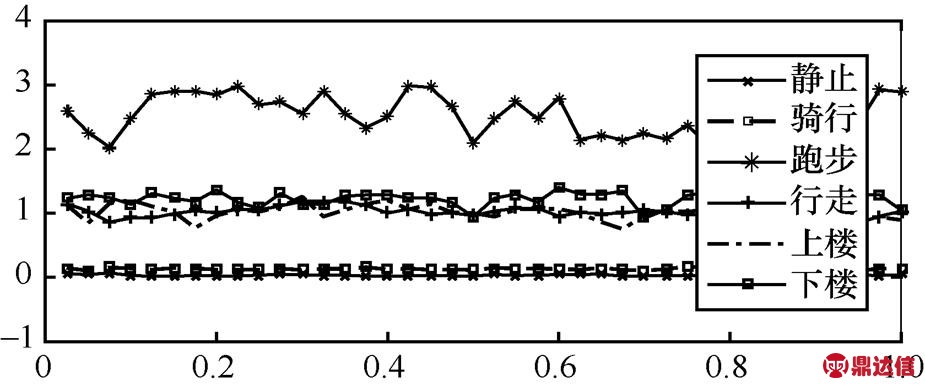
图13 6种运动状态下的标准差
下面,进一步分析静止和骑行运动状态特征。虽然手机不一定处于水平状态,但在静止状态下加速度和重力加速度数据保持一致,两者在传感器三轴方向的加速度只有微弱的波动。线性加速度矢量和反映了静止状态下人体对手机的作用结果,从图14可以看出,人体处于静止状态时,最大值均值在0.1~0.2 m/s2范围内波动,因为人体在相对静止状态下,身体仍存在一定的晃动。骑行过程中,最大值均值在0.3~0.5 m/s2范围内波动,其呈现的规律与静止状态没有明显区分,但是骑行状态最大值均值的变化范围比静止状态大,但这2种状态的最小值均值、平均值和标准差3个特征向量的变化趋势和变化范围都有明显区别,如图15~图17所示。从以上分析可知,静止和骑行这2种运动状态比较容易区分。
图14 骑行和静止状态下的最大值均值
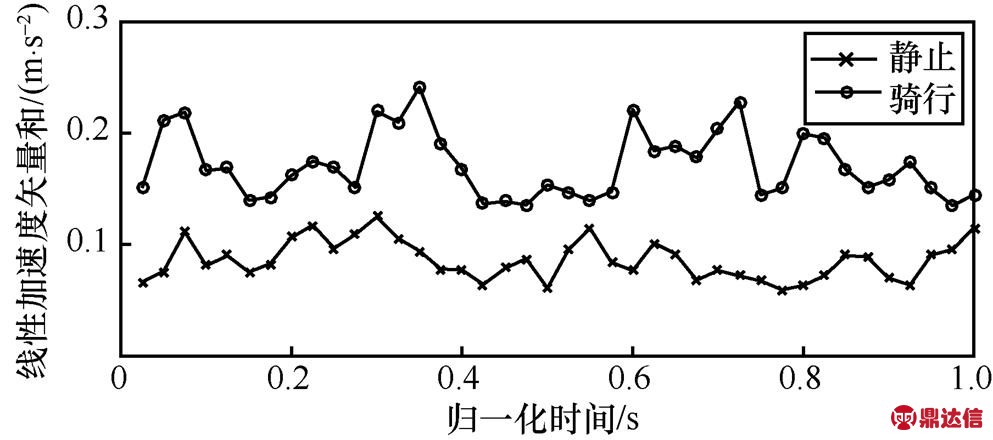
图15 骑行和静止状态下的最小值均值
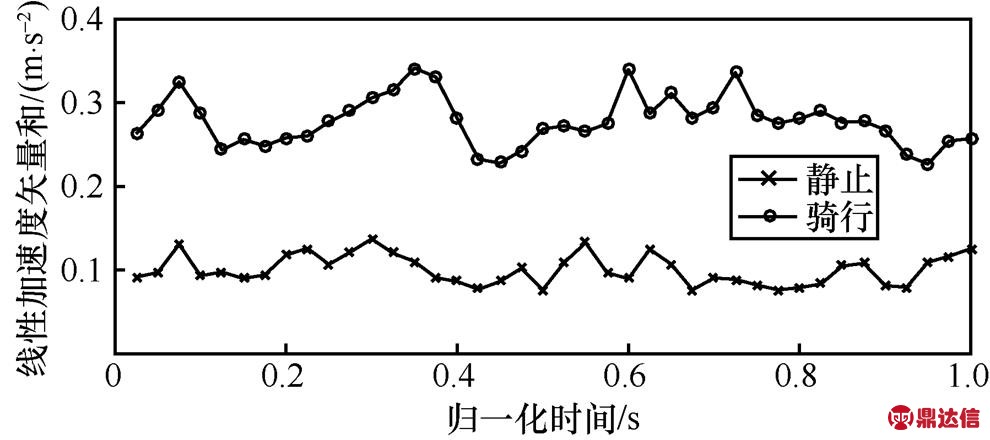
图16 骑行和静止状态下的平均值
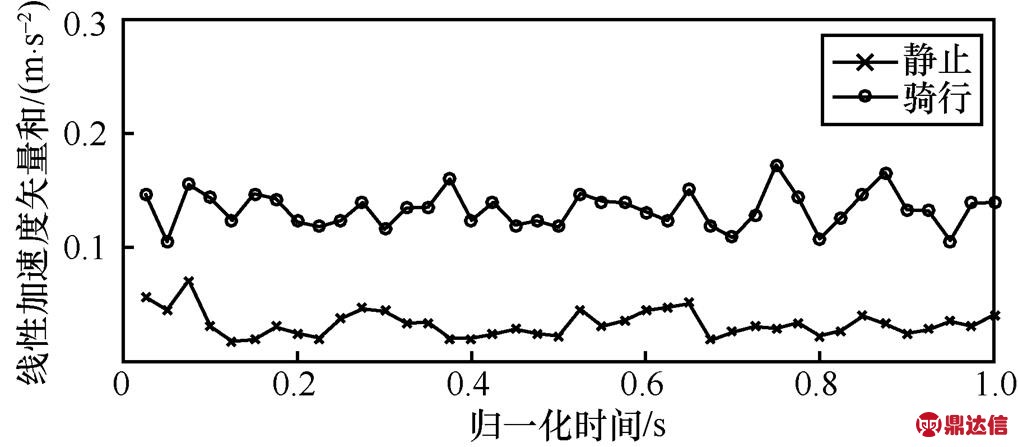
图17 骑行和静止状态下的标准差
由图10~图13可知,行走、上楼和下楼这3种运动的4个特征向量之间没有明显区分。进一步研究3种运动状态的最大值均方根、四分位差、偏度和峰度,各特征向量如图18~图21所示。从图中无法直接对这3种运动状态进行有效区分,但可以借助SVM(support vector machine)工具,把3个方向上共24个特征向量映射到高维空间进行识别。
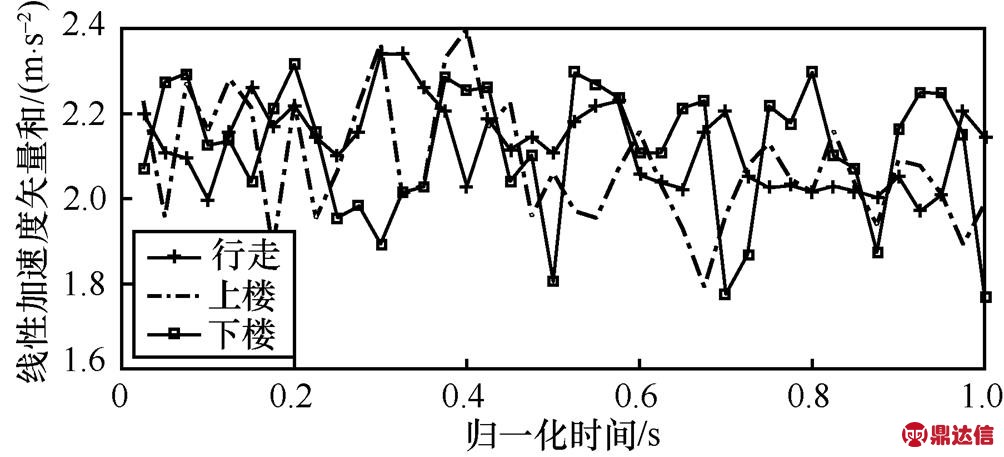
图18 行走、上楼和下楼的最大值均方根
由于SVM具有样本小、结构风险小和非线性的特点,在高维模式识别中较其他传统机器学习算法有明显的优势,分类思想简单,分类效果较好。目前,SVM分类策略包括一对一(OVO,one-versus-one)、一对多(OVR,one-versus-rest)和H-SVM等方法。本文选择H-SVM方法,将运动状态划分为如图22所示的多层识别模型。利用各种运动状态下的共24个特征向量和运动学的先验知识,对运动类别进行划分,每次划分时子类别内部的运动状态具有较大的相似性,子类别之间则具有较大的区分,从而尽可能地区分不同的运动状态。
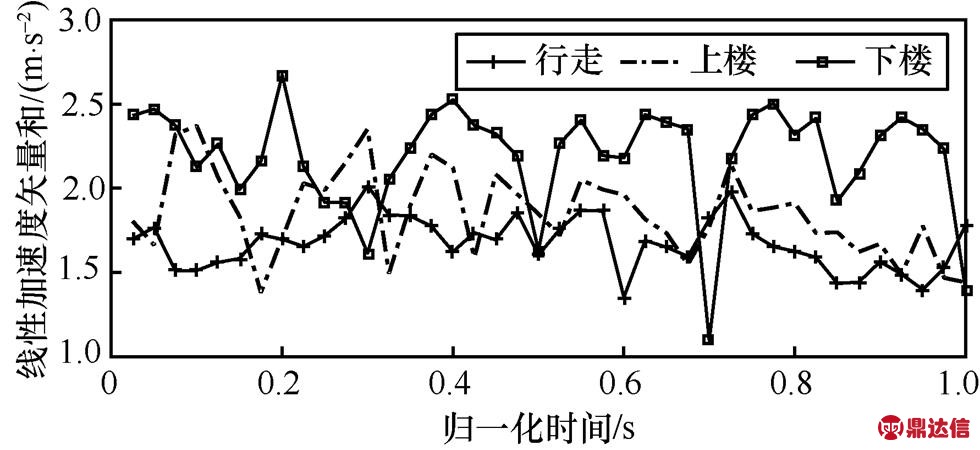
图19 行走、上楼和下楼的四分位差
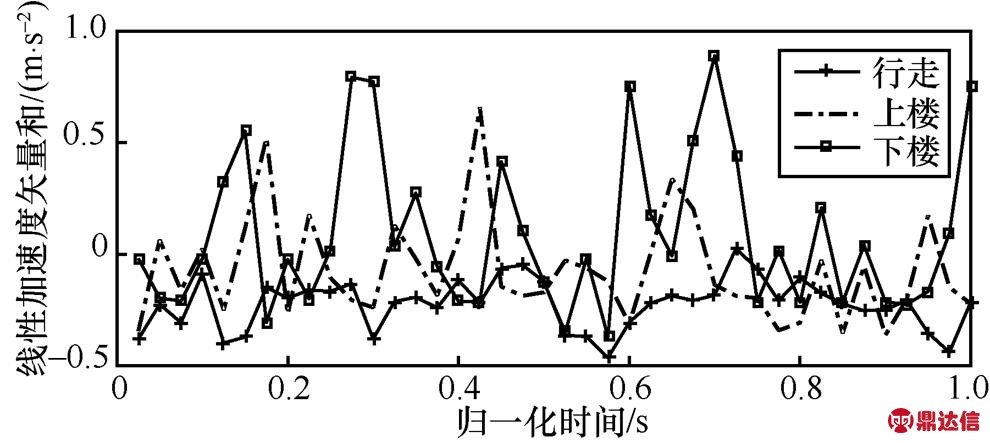
图20 行走、上楼和下楼的偏度
图21 行走、上楼和下楼的峰度
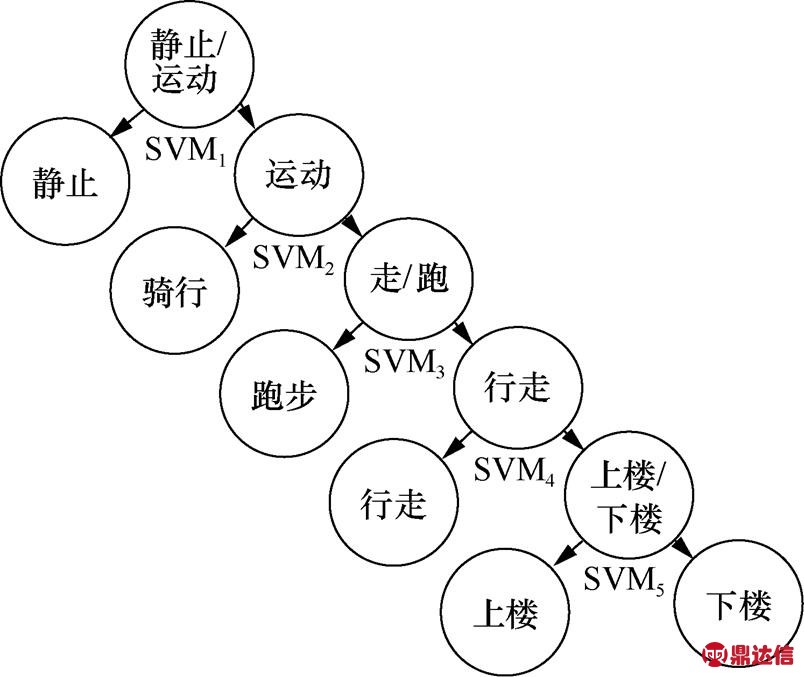
图22 层次向量对运动状态的划分
5 实验及分析
为了评估系统的有效性,进行了如下实验。首先,用H-SVM方法验证不同的手机携带方式下6种运动状态识别的准确率;其次,验证了H-SVM、Naïve Byes、Decision Tree和KNN识别方法对6种不同运动状态的识别准确率;再次,验证了3.2节DE-PSO算法在数据校准上的优势,验证了3.5节的坐标转换算法和4.1节的脚步识别算法在H-SVM识别方法中的作用;最后,分析了时域特征向量和频域特征向量计算的时间复杂度,并从多个方面将本文方法与相关文献的方法进行比较。
5.1 不同手机携带方式实验
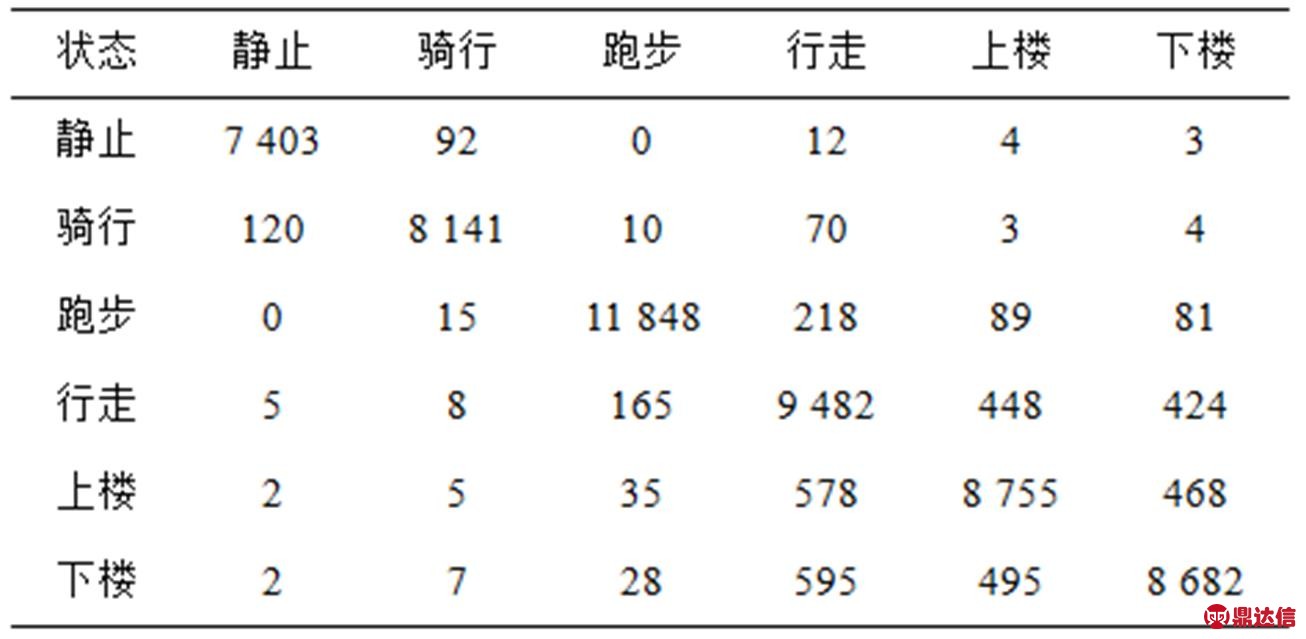
为了对系统进行全面评价和分析,本文按照5种手机携带方式和综合方式(即把5种携带方式下采集的6种运动状态数据按照运动状态综合)进行了6组实验,在每一组实验中将6种运动状态数据按照图22的H-SVM的分类方式划分训练集,即在每种手机携带方式下均需要训练5个二分类的支持向量机,分别用于识别静止状态和运动状态、骑行状态和行走/跑步状态、行走状态和跑步状态、行走状态和上/下楼状态、上楼状态和下楼状态。实验采用十折交叉验证方法,将训练的样本集分为10组,每次选取其中的9组作为训练集,剩余的一组作为测试集。使用H-SVM,选择SVM类型为C-SVC、核函数类型为RBF(径向基)核函数,其中损失参数C为32,核函数中参数g为0.5,经过多次实验验证,以上SVM参数能达到很好的优化效果,提升不同运动状态的识别准确率。手机放置在不同位置时H-SVM方法识别不同运动状态的准确率如表2所示。为进一步研究不同运动状态识别的差错情况,表3给出了综合方式下不同运动状态的混淆矩阵,矩阵中的行表示某种运动状态数量,矩阵中的列表示H-SVM方法识别某种运动状态数量。
表2 手机放置在不同位置下H-SVM方法的准确率

表3 综合方式下不同运动状态的混淆矩阵
从表2可以看出,在不同运动状态的识别中,识别准确率最高的是静止状态,其次是跑步和骑行状态,因为这3种运动状态时间窗口内最大值均值、最小值均值、平均值和标准差的取值范围与其他运动状态相比有明显的区分。行走、上楼和下楼识别准确率相对较低。
不同的手机携带方式下,运动状态的识别准确率不同。当手机放置在腰部时,运动状态识别准确率最高,当手机放置在上臂时,运动状态识别准确率最低,原因是手机放在腰部时采集的加速度数据最能反映人体的运动状态,而手机放在上臂时,加速度数据不仅反映了人体的运动状态,而且反映了上臂的运动状态。综合方式下识别的准确率仅次于手机放置腰部识别的准确率,但它不是手机放置不同位置的识别率的平均值,因为综合方式识别中训练数据不仅包含了测试数据,而且包含了更多的其他运动状态数据,数据测试模型的顽健性较强,减少了异常数据的干扰。虽然综合方式下识别准确率不及手机在腰部的识别准确率高,但是它很好地反映了日常生活中携带手机的随意性,且准确率达到93.37%。
从表3可以看出,许多预测误差是由于行走、上楼和下楼这3种活动之间的混淆所致。由于这3种运动较为相似,特征向量区别不是很明显。受到实验条件的限制,上楼和下楼的识别准确率最低,因为楼道中间有平台,在平台上的运动状态更接近行走。
5.2 不同的分类算法对比实验
为了评估本文方法的有效性,把本文的H-SVM识别方法与Naive Bayes、Decision Tree和KNN进行对比实验,Naive Bayes方法中使用GaussianNB算法,Decision Tree中使用CART(classification and regression tree)算法,在KNN中使用ball-tree算法,其他参数使用默认值。对综合方式下的数据,采用十折交叉法对实验进行验证,得到不同识别方法的准确率,如图23所示。
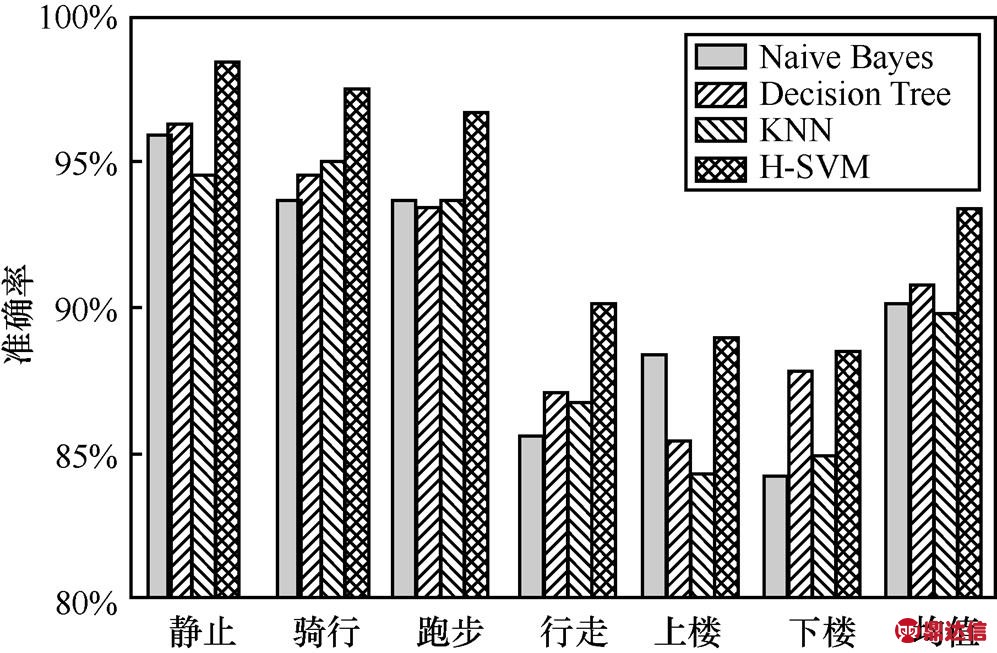
图23 综合方式下不同分类方法的准确率
从图23可以看出,4种不同的识别算法中,H-SVM识别率最高,因为使用H-SVM方法时训练数据根据图22所示对数据进行分类,使相同类别的内部运动状态具有较大的相似性,不同类别之间具有较大的差异性,相对于其他识别方法,提高了识别准确率。
5.3 DE-PSO算法和高斯−牛顿迭代法对比实验
为验证DE-PSO算法的有效性,根据文献[36]方法复现实验。将手机固定在长方体木块的一个面上,然后分别将长方体的6个面水平放置在桌面上,得到6种放置方式,如表4所示,采集到手机在6种放置方式下一定时间内的加速传感器数据,并取其平均值,得到6组加速度传感器的测量值。使用DE-PSO算法和高斯−牛顿迭代法对采集的加速度传感器数据进行校准,校准后数据如表4所示。
表4 DE-PSO算法与高斯−牛顿迭代法对比
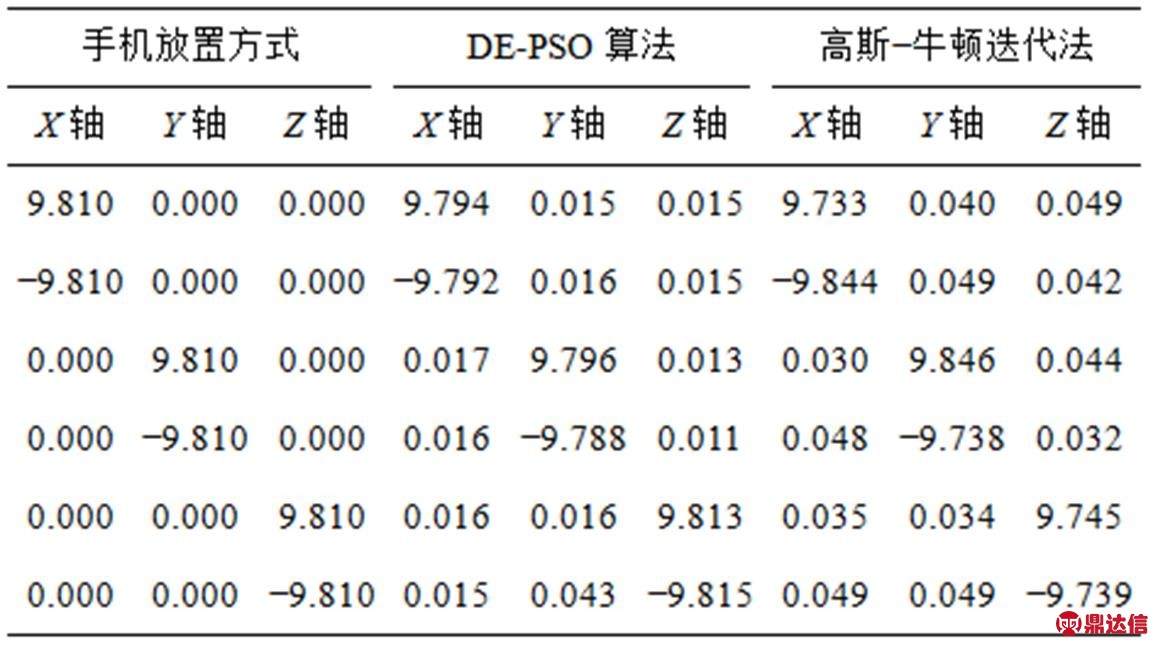
由表4可知,高斯−牛顿迭代法能够实现加速度数据的校准,但是校准结果与DE-PSO算法相比误差较大。仿真时发现,高斯−牛顿迭代法运行速度较慢,仿真时间长,容易出现实验进行不下去的现象,这是因为该算法本身存在不足。通过对比可知,DE-PSO算法运行速度较快,仿真时间较短,误差较小。
5.4 不同数据处理方法实验
为检测惯性坐标系下的线性加速度能否准确反映人体运动状态的变化情况,以及脚步识别算法中计步的准确性,本节对与手机方向无关性算法和脚步识别算法进行验证。
5.4.1 与手机方向无关性实验
与手机方向无关性处理的效果如何,最终体现在人体运动状态识别准确率的高低。本文首先使用5.1节中的综合数据,按照文献[9-12]方法对数据进行与方向无关处理,然后使用本文提出的分层识别方案对人体的运动状态进行识别。同时为了验证3.2节数据校准对人体运动状态识别的影响,本文对校准前后的数据进行了对比实验。各种方案的识别准确率的结果如表5所示。
表5 5种不同处理方法识别准确率
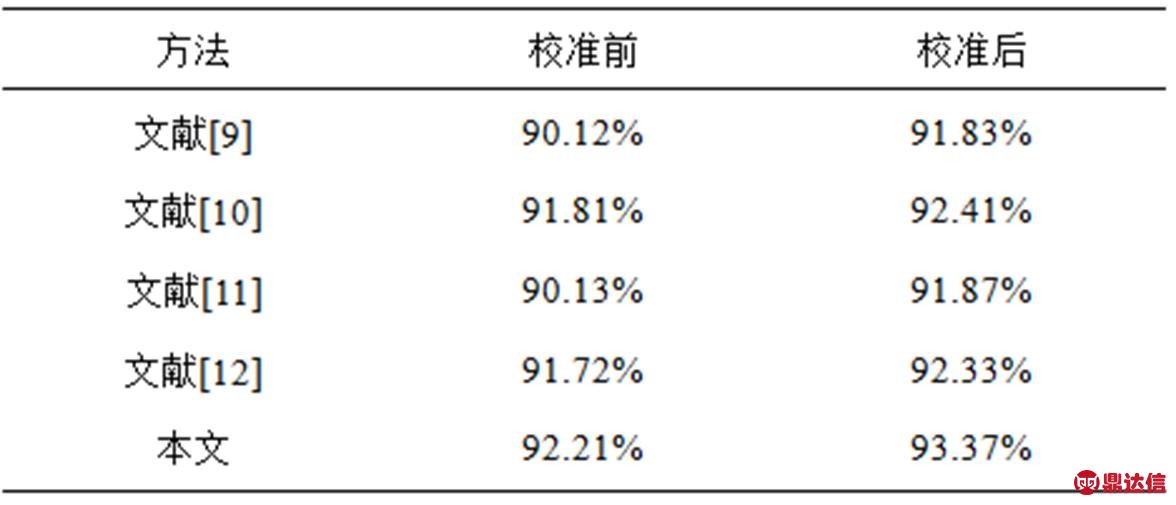
通过表5可以看出,本文方法的运动状态识别准确率最高,识别效果最好。本文利用同一采样点的重力加速度与加速度关系,能够准确计算出惯性坐标系下的线性加速度。由校准前后的数据对比可知,数据经过校准后运动状态识别率明显提高。
5.4.2 脚步识别算法实验
为验证本文的脚步识别算法的实用性,实验时手机分别放置在胸口、上臂、裤前袋、裤后袋和腰部5个不同位置,手机方向随机。本实验对10位实验者在每种手机携带方式下以不同的频率进行200步数据采集,得到5种手机携带方式共10 000步数据样本。对采集的数据进行校准、滤波与方向无关性处理,使用惯性坐标系下的线性加速度,应用本文的脚步识别算法对采集数据进行步数统计,实验结果如表6所示。本文的脚步识别算法的平均准确率高于文献[41-42]算法的平均准确率。文献[41-42]算法在计步判断的过程中没有对原始加速度信号进行滤波和与方向无关性处理,在一定程度上影响了算法检测的准确率。
表6 3种脚步识别算法的计步准确率
本文脚步识别算法利用人体运动频率的范围,判断下一脚步的波峰(谷)距当前脚步波峰(谷)的位置范围,在此范围内寻找波峰(谷)的最大(小)值,此值为下一脚步的波峰(谷)位置。因此,该算法可以更精确地计算运动的脚步数,减少了伪波峰对真实波峰的影响。
结果表明,经过转换的线性加速度能够准确、有效地反映人体运动状态。脚步识别算法能够准确地计算不同运动状态的脚步数,并能有效计算最大值均值和最小值均值,提高人体运动状态识别的准确率。
5.5 特征向量计算复杂度分析
在使用频域特征向量时,大部分研究都使用了快速傅里叶变换(FFT, fast Fourier transform)方法,这种算法运用数学方式把原来复杂度为O(n2)的朴素多项式乘法转化为复杂度为O(nlbn)。根据4.1节中的描述,可以计算出对应的特征向量时间复杂度为O(n)。本文采用的特征向量全部为运动数据时域上的特征向量,相比使用频域上的特征向量,在算法时间复杂度上有所降低。
将本文方法数据采集时手机携带位置、识别度运动状态的数量、使用的特征向量、特征向量计算复杂度和运动状态识别准确率等指标与近几年的文献进行比较,如表7所示。从表7可以看出,虽然本文方法的识别运动状态的准确率排名第二,但是其他各项指标都优于准确率排名第一的文献[11]的方法。
表7 本文方法和相似文献方法的比较
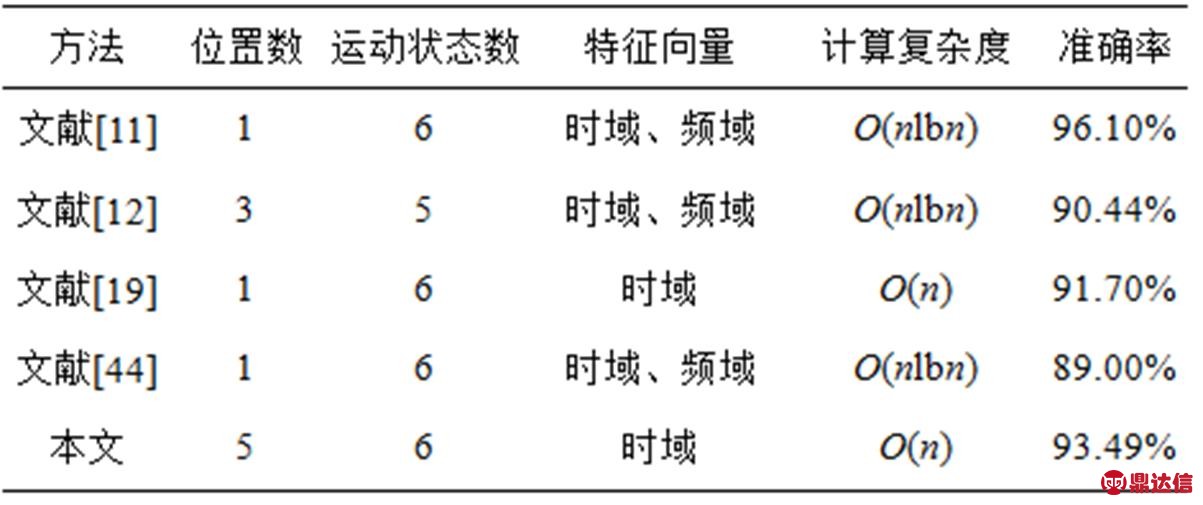
为验证本文方法的优势,本文复现了表7中文献的方法,使用本文中的综合数据,采用十折交叉法对6种运动状态进行识别,识别的结果如表8所示。从表8可以看出,本文提出的识别方法最优,其次是文献[12]。
表8 相似文献对6种运动状态识别比较
通过以上实验和分析可知,利用智能手机内置的加速度传感器和重力传感器,采用分层识别方案,能有效地识别人体6种日常运动状态。
6 结束语
本文研究了智能手机放置方向和位置都不确定的情况下,利用手机内置的加速传感器和重力传感器采集用户日常6种运动状态数据,根据ReliefF算法提取运动状态的时域特征向量,利用这些特征向量的值构造出一个最佳的识别模型,并使用该模型识别用户的运动状态。首先,选取了日常生活中常用的5种手机携带方式采集用户运动数据,并对采集的数据进行有效处理;然后,利用脚步识别算法,准确计算脚步的波峰和波谷值;最后,利用时间窗口内脚步的波峰和波谷值的时域特征向量和H-SVM分类算法对人体运动状态进行识别。实验结果表明,本文方法在保持较高的识别准确率的同时,极大地提高了手机在识别人体运动状态时对手机位置和方向变化的适应能力,同时利用数据时域上的特征和滑动加权均值有效地降低了手机的负载。本文的研究可应用于移动领域的用户行为状态识别、健康生活提示、随身运动监测和体感游戏等。
本文实验对实验者的选择有一定的局限性,在后续的研究中应该对更多的不同年龄阶段的人群进行对比实验,增加更多的实验环境,使实验数据更具有代表性。此外,还将进一步优化脚步识别算法,提高脚步识别的准确率,增强系统的灵活性;进一步增加可识别的人体运动状态、识别复杂的人体行为以及人体不同的运动与能量消耗之间的关系,为用户的运动与健康提供科学的指导。


