
摘 要:为了提高片上TCAM的摆放密度和降低功耗,基于IBM 32 nm工艺库提供的TCAM的特性和优先编码器硬核,设计出同时满足多个查找宽度的外围控制电路。相比于之前的设计和实现,该设计可以减少TCAM的块数和相关寄存器的数量,减少片上TCAM的摆放面积,降低芯片的整体功耗。该设计已经成功应用于公司第4代路由交换ASIC芯片上。
关键词:片上TCAM;优先级编码器;ASIC
1 TCAM简介
三态内容寻址存储器 (TCAM)是一类特殊的存储器,传统的存储器都是根据地址读出内容,例如静态存储器(SRAM)和动态存取器(DRAM),但是 TCAM是根据存储的内容得到对应的地址,输入一个数据(称为查找内容或者查找key),TCAM内部就把这个 key和它所有存储的条目作并行比较,然后把匹配的地址输出,如果有多个条目都与这个查找key匹配,那么输出最小的地址。
TCAM又有外挂和片上(内嵌)之分,外挂TCAM原来有多家厂商提供,经过一系列的并购,目前只有博通公司和瑞萨电子可以提供商用的TCAM芯片。外挂TCAM一般适用于交换容量在100 Gb/s量级的路由交换芯片或者安全芯片。对于带宽超过100 Gb/s以上的路由交换芯片或者安全芯片而言,直接在芯片内部集成TCAM不失为一种好的选择,特别是做并行访问控制列表(ACL)查找时,就特别需要片上TCAM。
片上TCAM有多个厂家可以提供不同的工艺库,其中IBM的片上TCAM工艺库是目前为止面积最优、功耗最小且速度最快的片上TCAM工艺库之一。
TCAM的基本单元由一个数据位(data)和一个掩码位(mask)构成,所以顾名思义称为三态存储器,当输入1 bit数据(input)时,当 input=data& mask,才算匹配。这时,TCAM会输出一个命中(hit)指示,表示这个条目命中,这个特性让TCAM在ACL、路由查表的最长前缀匹配和模糊查找中特别有用。
但是TCAM也有不足之处,主要体现在两个方面:一个是相比较于SRAM和DRAM,它的存储密度很低,摆放密度也低;另外,TCAM做查找的时候,功耗特别大(因为需要所有的条目并行作比较)。
图1显示IBM 45 nm工艺下的TCAM与SRAM、DRAM的比较,TCAM只有1.10%的存储容量(百万比特数),却占用所有存储器8.64%的面积(如果考虑到摆放面积,这个数字还要加倍)和消耗10.31%的功耗。
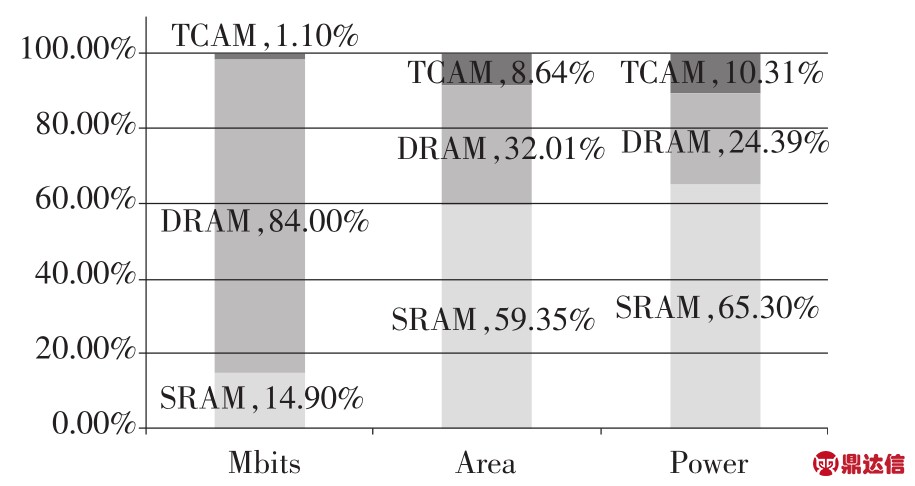
图1 TCAM和SRAM、DRAM的比较(IBM 45 nm)
本文基于IBM 32 nm工艺库提供的TCAM的一些新特性和提供的优先级编码器硬核,通过特别设计的电路,可以同时满足 160 bit、320 bit和 640 bit数据的查找,并且减少TCAM的块数、降低TCAM的功耗。
2 片上TCAM外围电路的设计
2.1 多种查找宽度电路设计
此前为了实现多种位宽key的查找,必须以最小key的位宽作为TCAM的位宽选择。例如,需要同时支持160 bit、320 bit和 640 bit 3种 key位宽的查找,需要选择TCAM的位宽必须是160 bit的,然后通过横向拼接的方式实现320 bit和640 bit位宽的key宽度查找。
IBM 32 nm工艺库提供的TCAM支持一种称为列使能的方式。以1 024深度320 bit宽度的TCAM为例,图2表示将320 bit宽度分成4列,每一列有80 bit位宽,4列分别是 FE0、FE1、FE2和FE3,其中 FE0和FE2是偶数列,FE1和FE3是奇数列。当进行160 bit查找时,FE0和FE2自动拼接成160 bit与key做匹配,并且结果输出到MLLA[1 023:0],每个 bit代表一个条目的查找结果,FE1和FE3自动拼接成另外一个160 bit与key做匹配,并且输出结果到MLLB[1 023:0],通过外部设计的电路,先把MLLA[1 023:0]中最小的匹配地址找出来(通过优先级编码器),同时把MLLB[1 023:0]中最小匹配地址找出来,最后比较MLLA和MLLB中哪个匹配地址最小,取小优先,如果值相等,则优先取MLLA的结果作为最终结果。
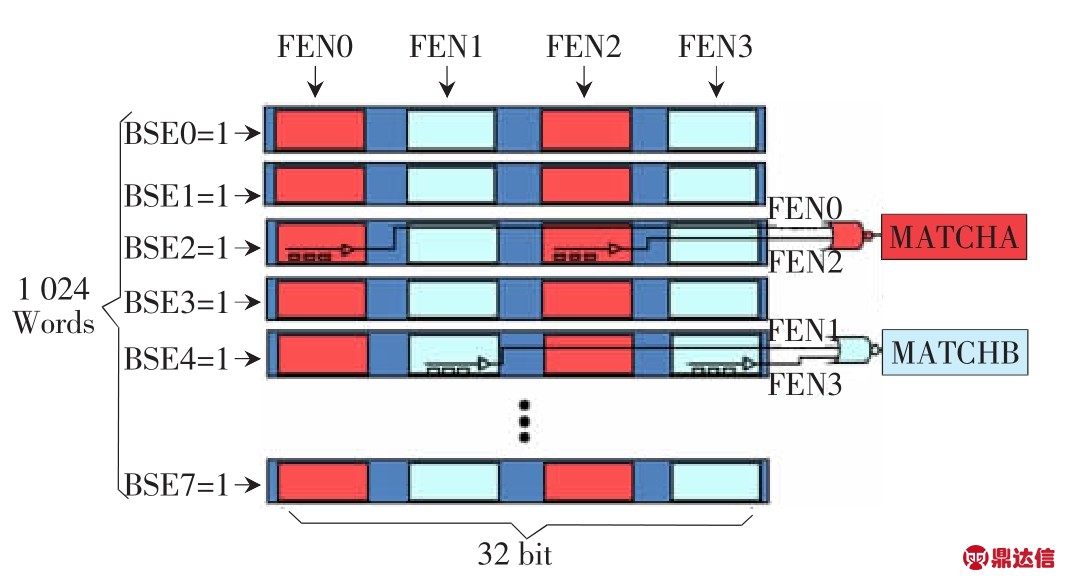
图2 TCAM列查找示意(IBM 32 nm)
这样,TCAM的最小宽度就不必是160 bit,可以是320 bit,与之前的需要 160 bit宽度的 TCAM相比,构建相同大小的查找表,TCAM的块数可以减少一半。
TCAM的块数多少直接影响到芯片的面积大小,前面提到过TCAM本身物理的面积就比DRAM和SRAM大,此外,TCAM由于在做查找时需要把输入的内容和存储的所有条目同时作比较,会导致片上供给TCAM的电源噪声变大。为了解决这个问题,一般需要在TCAM之间插入大的片上去耦电容,再加上需要把优先级编码电路和相关的寄存器紧靠着TCAM摆放,因此需要TCAM块与块之间有一定的间隔。图3显示了在45 nm工艺下16块TCAM在硅片上的摆放面积是 3.231 5 mm2(=2.81 mm×1.15 mm),相比较于 TCAM本身的面积(1.59 mm2),大了将近一倍。所以,从这个层面上而言,构建相同大小的查找表,TCAM的块数越多越不好。

图3 片上TCAM摆放面积(2.81 mm×1.15 mm,IBM 45 nm)
此前为了解决TCAM查找结果MLL(匹配位)输出的时序问题,可行的做法是将匹配的结果先用寄存器锁存起来,再送给后续的优先级编码器。IBM 32 nm的工艺库新提供了6~64的优先级编码器硬核,可以解决时序问题。
图4显示 IBM 32 nm提供的6~64的优先级编码器硬核,输出信号 HIT表示所有 MLL[63:0]作位“或”运算之后的结果。

图4 IBM 32 nm优先级编码器硬核(IBM 32 nm)
图5(a)中显示了采用用户自己设计的6~64的优先级编码器时,必须将TCAM输出的匹配结果先用寄存器锁存一拍,然后才送给优先级编码器。图 5(b)显示,采用IBM 32 nm提供的优先级编码器硬核,可以直接把TCAM的匹配结果经过一个或者两个与门之后与优先级编码器的输入对接,优先级编码器的输出再进入寄存器锁存起来。
表1比较了两种方案所需要的资源,可以看到,TCAM的匹配结果需要的锁存寄存器可以全部节约下来,只要TCAM的深度越大,节约的寄存器就越多,以支持 16 384个 160 bit宽度的 ACL条目为例,方案(a)需要额外多出16 384个寄存器。

图5 优先级编码器硬核及相关电路比较
表1 两种方案所需要的资源比较

此外,方案(a)比方案(b)会多一级流水线的延迟。
采用图 5(b)所示的电路,可以实现 160 bit、320 bit和640 bit 3种key宽度的查找。
160 bit宽度key的查找流程如下:
(1)TCAM#0 输 出 匹 配 结 果 MLLA_0 [63:0]和MLLB_0[63:0], 同时,TCAM#1 输出 MLLA_1[63:0]和MLLB_1[63:0]。
(2)MLLA_0[63:0]经 过 6~64 优 先 级 编码 器,输 出indexA_0[5:0]和 hitA_0(图中没有标示出来)。 同样地,对于 MLLB_0[63:0]、MLLA_1[63:0]和 MLLB_1[63:0]经过各自对应的优先级编码器, 输出 indexB_0[5:0]、indexA_1[5:0]和 indexB_1[5:0], 以及对应的 hitB_0、hitA_1和 hitB_1。
(3)indexA_0[6:0]和 indexB_0[6:0]比较,如果 hitA_0和hitB_0二者只有一个为1,那么选择对应的index输出;如果 hitA_0和 hitB_0均为 1(表示都有匹配到),则选择indexA_0输出。当选中indexA_0时,输出indexAB_0[6:0]={indexA_0[5:0],1′b0}, 最 低 位补0;当选中indexB_0时,输出indexAB_0 [6:0]={indexB_0[5:0],1′b1},最低位补1,此外还需要把 hitA_0和hitB_0作位“或”运算输出 hitAB_0。
(4)对 于 indexA_1 [6:0]和indexB_1[6:0]有同样的操作,得到结果 indexAB_1[6:0]和 hitAB_1。
(5)比 较 indexAB_0 [6:0]和indexAB_1[6:0],操作过程类似于步骤(3), 最 后 得 到 index160 [7:0]和hit160。
320 bit宽度key的查找流程如下:
(1)TCAM#0 输 出 匹 配 结 果MLLA_0[63:0]和 MLLB_0[63:0], 同时 ,TCAM#1 输 出 MLLA_1[63:0]和MLLB_1[63:0]。
(2)MLLA_0[63:0]每 个 比 特 和MLLB_0[63:0]的每个对应比特位进行“与”运算,得到 MLLAB_0[63:0],再输入到一个专门的6~64优先级编码器 ,输 出 index320_0[5:0]和 hit320_0(图中没有标示);对于 MLLA_1[63:0]和MLLB_1[63:0],有 同 样 的 操 作 ,把 MLLAB_1[63:0](=MLLA_1[63:0]&MLLB_1[63:0])输出 index320_1[5:0]和 hit320_1。
(3)比 较 index320_0[5:0]和 index320_1[5:0], 过 程与前述类似,得到 index320[6:0]和 hit320。
640 bit宽度key的查找流程如下。
(1)将前述 320 bit宽度 key查找流程的步骤(2)得到的 MLLAB_0[63:0]和 MLLAB_1[63:0]再作一级按位“与”操作(MLLAB_0[63:0]& MLLAB_1[63:0]),结果输出到优先级编码器中,得到 index640[5:0]和 hit640。
最后还有一级多路选择器,根据全局配置,在index160[7:0]、index320[6:0]和 index640[5:0]三 者 之 间选择一个作为最终结果输出
上面设计的TCAM查找电路,与之前的设计相比,在需要同样大小的查找表情况下,TCAM的块数少一半,而且由于应用了优先级编码器硬核,可以把第一级的锁存寄存器全部省掉,此外还降低了TCAM的摆放面积和功耗。
2.2 利用TCAM的预查找功能降低查找功耗
IBM 32 nm工艺库中的TCAM为了防止查找时的瞬间功耗过大,提供了一种预查找功能。TCAM横向的块称为一个Bank,每个Bank包含128个条目,每个条目无论多少位宽,可以按照80 bit来切分,每80 bit的存储数据可以分为两级进行查找,第一级查找称为预查找,只匹配低 bit0~bit7总共 8 bit,如果这 8 bit没有匹配,则后面的72 bit就不会参与比较运算。
因此,每80 bit位中的低8 bit又可以称为预查找比特位,这个功能对于用户而言是透明的,但是需要用户精心安排数据结构,才能充分发挥这个特性,例如,把不同数据结构的标志号放在这低8 bit。
从统计学上分析,如果所有数据足够随机化,每256个条目只会有一个条目匹配,也只有这个条目的后72 bit才会参与比较,这样消耗的功耗只有原来的10%(=(256×8+72)/(256×80))。
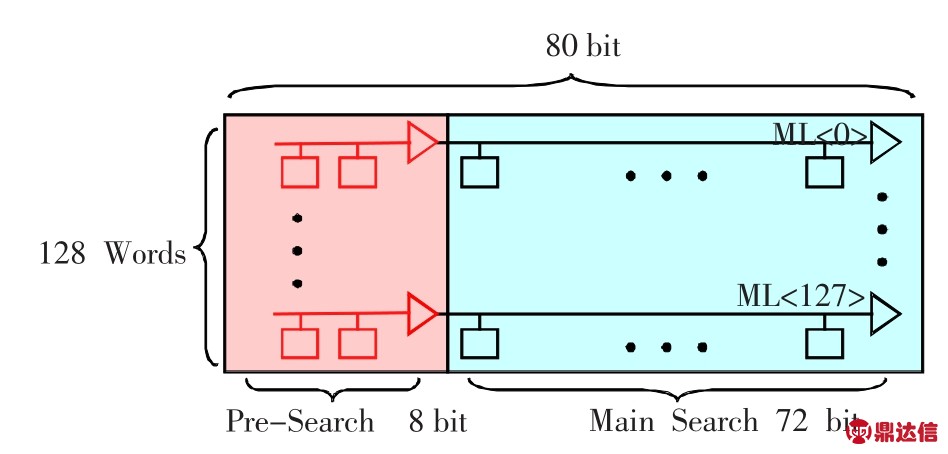
图6 TCAM预查找功能示意(IBM 32 nm)
值得一提的是,IBM 32 nm工艺库的TCAM还同时提供功耗门控和深度休眠的方式来降低TCAM的动态功耗,前者对于使用者是透明的,后者需要设计相应的控制电路,而且从深度休眠的模式恢复到正常工作模式,至少需要100 ns的唤醒时间。
本文基于IBM 32 nm工艺库提供的TCAM和优先级编码器硬核,通过设计相应的外围电路,充分利用该TCAM的特性和硬核IP,减少所需TCAM的块数和外围寄存器的数量,节省了TCAM在硅片上的摆放面积,同时降低了TCAM的功耗。本文提到的全部设计已经在公司的第4代以太网路由交换ASIC芯片上实现。
后续的工作,将研究如何基于厂家提供的TCAM如何进一步提高TCAM的查找性能。另一方面,将研究一些性能要求不高的场合下,如何充分利用TCAM的深度休眠功能,进一步降低整个芯片的功耗。


