
摘 要:一般交通流数据质量检测方法要求的原始数据量较大,而无检测器道路可获得的交通流数据又非常有限。为此,提出一种基于灰色系统理论的无检测器道路交通流数据质量检测方法。该方法将不同检测点获得的原始交通流数据处理成一组数据序列,通过对数据序列的灰生成、灰色关联度计算及标准化处理,求得不同数据序列相互间关系的密切程度参数λi,根据需求选出阈值λ,比较λi与λ之间的大小,实现无检测器道路交通流异常数据检测的目的。运用杭州市某一局部路网的浮动车交通流原始数据,将该方法与基于相似系数和的检测方法进行对比实验,结果证明,该方法的检测效果优于基于相似系数和的检测方法,平均错检率降低了21.00%,平均准确率提高了28.64%。
关键词:智能交通;交通流;脏数据;数据清洗;数据质量;灰色系统理论
1 概述
自20世纪30年代智能交通诞生起便在全球迅速引起关注[1],经过几十年的发展,它已经成为人们生活中的一部分,成为解决交通拥堵、交通事故、交通污染等问题的有效途径之一。实时准确的短时交通流预测作为实现城市交通控制与道路诱导系统的关键,是智能交通系统(Intelligent Transportation System, ITS)建设的核心内容[2]。目前,交通流预测的模型和方法已经非常丰富[3-5],综合起来有:线性方法,如时间序列预测方法[6];非线性方法,如小波分析方法[7];智能模型方法,如神经网络法[8];组合方法,如季节性支持向量机和混沌免疫算法的组合应用[9]。科学技术的迅速发展,交通流数据的来源呈多元化趋势(如线圈、视频等),这使得基于数据融合技术的交通流预测成为另一种有效提高预测精度的途径[10-11]。然而,现实中常常由于交通流数据检测器处于非正常工作状态或传输通信设备的故障、环境因素的变化等原因,检测器获得的数据不可避免地存在丢失、冗余、错误等质量问题,通常称为脏数据。显然,质量不高的交通流数据不但会影响短时交通流预测效果,而且会给智能交通系统后续的交通应用(如数据融合)带来诸多问题[12-14]。鉴于此,国内外学者就如何检测交通流异常数据、清洗脏数据,提高数据质量进行了一定的研 究[15-16]。总之,国内外对有检测器道路交通流数据的预测与质量研究较多。
在智能交通建设过程中,国外部分先进国家的大部分交叉口都安装了检测器,道路基础交通流数据都可通过检测器获得。而我国城市路网过大、交叉口过多、政府资金投入不足等因素导致检测器并非覆盖所有交叉口[17],无检测器道路交通流数据的获取手段显得非常有限(如浮动车、人工采集等)。无检测器道路交通流数据的缺失,不利于无检测器道路的交通流预测,不利于我国城市整个路网智能化管理的实现。国内部分学者对无检测器道路的交通流预测进行了研究[18-20],而他们仅在预测前对交通流某一种或几种数据质量问题进行了简单处理,并没有给出一套完整的无检测器道路交通流脏数据清洗方法[21-22]。
本文在已有研究成果的基础上,充分考虑无检测器交通流数据的随机性和灰色特征[18-19],基于灰色系统理论提出无检测器道路交通流数据的灰色清洗规则,并运用杭州市某一局部路网的浮动车交通流数据与已有基于相似系数和的方法进行对比实验。
2 灰色清洗规则
在脏数据的清洗过程中,清洗规则发挥了关键作用。文献[12]针对交通流数据的错误、丢失、冗余这3种经常发生的现象给出了相应的清洗规则,该方法对于通过检测器(环形线圈检测器)获得的大量道路交通流数据是有效的。而无检测器道路交通流数据通常是由浮动车或人工采集的方式获得,数据量不但相对不足,而且随机性和灰色特征更加突出,这就要求有适合无检测器道路交通流数据的清洗规则。
浮动车作为一种新型的城市交通信息采集平台,得到了国内外ITS专家和企业的高度重视[23]。目前,北京、上海、杭州、宁波、西安等城市已经拥有了一定规模的浮动车采集终端(由于个人出行的隐私性,出租车是当前唯一能够支持大规模应用的浮动车数据采集源),这些浮动车为获得城市无检测器道路交通流数据提供了有效途径。浮动车GPS数据生成格式[24]及举例如表1所示。
表1 浮动车GPS数据生成格式及举例
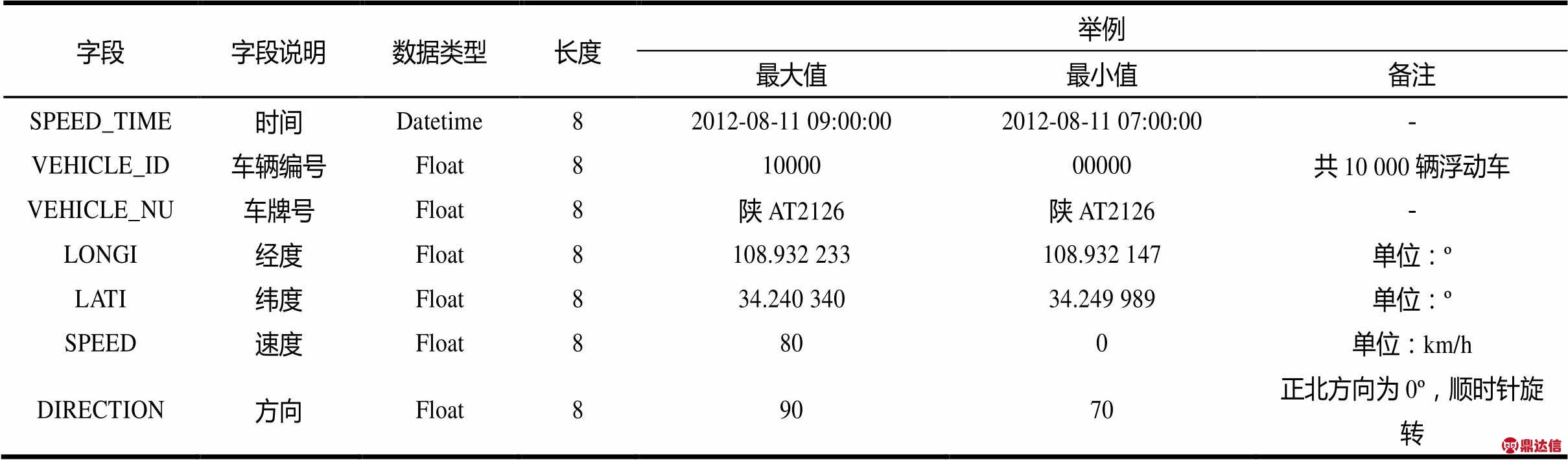
然而,由于民用GPS精度限制、地面建筑物遮挡、车载GPS设备故障,及部分浮动车驾驶员在道路上任意停放、不规则变道和加减速等随意性较大的驾驶行为等原因[25],浮动车交通流存在脏数据在所难免。因此,本文基于浮动车GPS数据格式提出了城市无检测器道路交通流脏数据清洗规则,如图1所示。
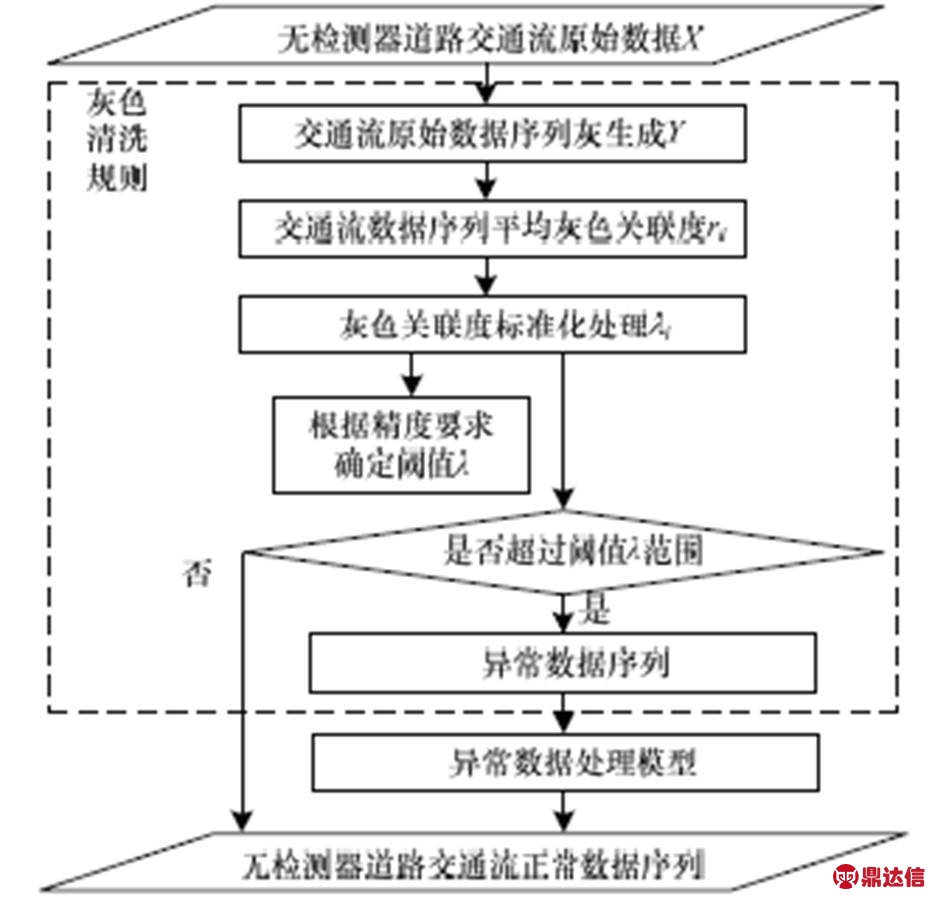
图1 城市无检测器道路交通流灰色清洗规则
灰色系统理论是针对既无经验,数据又少的不确定性问题,即少数据不确定性问题提出的[26]。灰色关联分析是灰色系统理论的一个重要内容,其基本思想是根据曲线间几何形状的比较进行因素分析,认为几何形状越接近,则发展变化态势越接近,关联程度越大。另外,灰色关联分析模型的建立,每一序列可少到3个数据。于是,本文选用灰色关联分析中的灰色自关联矩阵,结合阈值理论[27]提出了无检测器道路交通流异常数据的灰色清洗规则。
设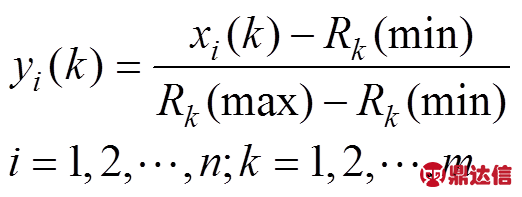 为某无检测器道路上检测点数(如浮动车数量、人工采集点等),每个检测点可获得的交通流数据有
为某无检测器道路上检测点数(如浮动车数量、人工采集点等),每个检测点可获得的交通流数据有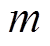 个属性,即:
个属性,即:
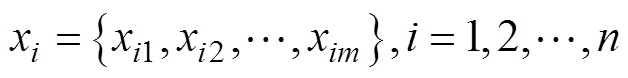 (1)
(1)
为进行灰色关联分析,对采集到的交通流数据需进行灰生成。本文结合阈值理论选用区间化生成规则,即:
(2)其中,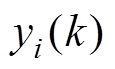 为灰生成后的交通流数据;
为灰生成后的交通流数据; 为第
为第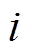 个检测点获得的交通流数据第
个检测点获得的交通流数据第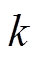 个属性的属性值;
个属性的属性值;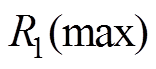 和
和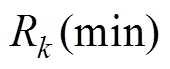 是可由阈值理论确定或实际可得的交通流第个属性的最大值和最小值。如浮动车GPS数据中,可根据阈值理论和城市道路交通规划设计规范[28]获得大城市主干道地点平均速度的
是可由阈值理论确定或实际可得的交通流第个属性的最大值和最小值。如浮动车GPS数据中,可根据阈值理论和城市道路交通规划设计规范[28]获得大城市主干道地点平均速度的 和
和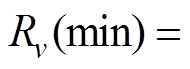
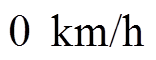 ;而对于浮动车行驶的各个路段的经度和纬度范围也很容易获得,如西安市含光路北段纬度
;而对于浮动车行驶的各个路段的经度和纬度范围也很容易获得,如西安市含光路北段纬度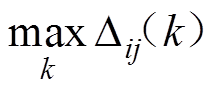
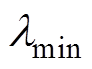 和
和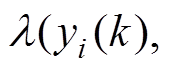 。
。
灰生成后,考虑到并不能确定哪些检测点获得的交通流数据质量较高,即并不能确定哪个检测点的数据可作为参考序列(标准序列),基于此,本文选用灰色系统理论中的灰色自关联矩阵实现对无检测器道路交通流数据质量的检测。灰色自关联矩阵法能够将每一检测点获得数据本身既作为比较序列又作为参考序列进行处理,进而可以知道各个检测点获得数据间关系的紧密程度。另外,对于多属性的交通流数据而言,多属性恰恰可以构成一个数据序列,通过计算不同检测点获得的交通流数据(不同数据序列)间的灰色关联度,便可了解交通流数据的整体情况。灰生成后,检测点xi与xj间的灰色自关联矩阵T构造[26]过程如下:
(1)计算检测点xi与xj间差异信息集,构造灰色关联差异信息空间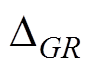 。
。
差异信息集:
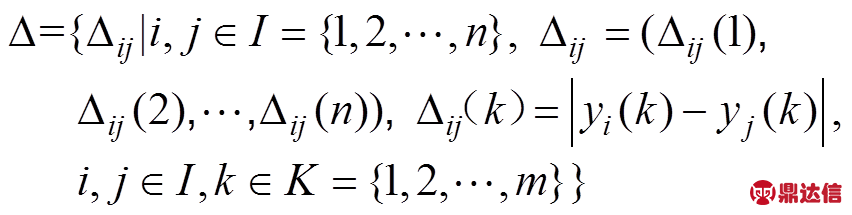 (3)
(3)灰色关联差异信息空间:
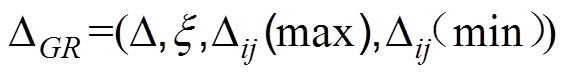 (4)
(4)
其中,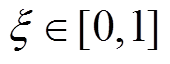 为分辨系数,常取0.5;
为分辨系数,常取0.5;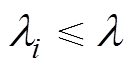 为上环境系数;
为上环境系数;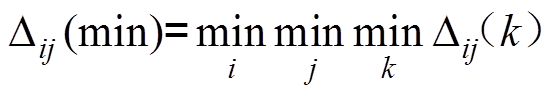 为下环境系数。
为下环境系数。
(2)计算检测点xi与xj间的灰色关联系数 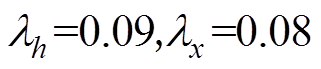 :
:
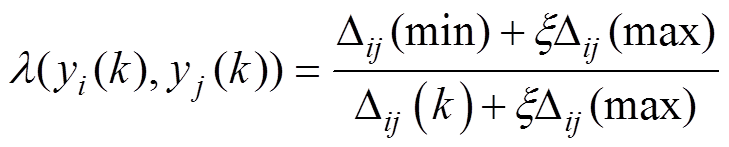 (5)
(5)(3)计算检测点xi与xj间的灰色关联度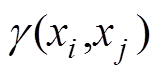 :
:
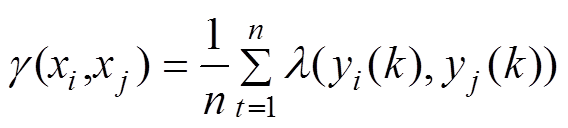 (6)
(6)
(4)构造检测点xi与xj间的灰色自关联矩阵T:
T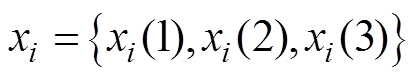 (7)
(7)
令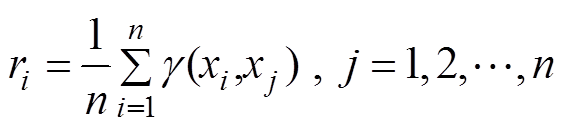 为监测点获得的交通流数据与其他检测点交通流数据间的平均灰色关联度,进一步通过
为监测点获得的交通流数据与其他检测点交通流数据间的平均灰色关联度,进一步通过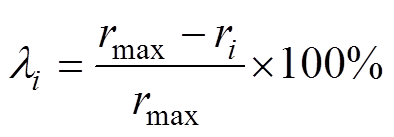 的标准化因子求得反应监测点与其他检测点间的关系密切程度的参数
的标准化因子求得反应监测点与其他检测点间的关系密切程度的参数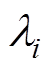 ,其中,
,其中,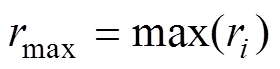 。若取
。若取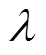 为阈值,则
为阈值,则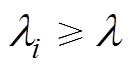 或的对象则被认为是异常数据序列。事实上,对于交通流数据而言,总可以找到合适的阈值和
或的对象则被认为是异常数据序列。事实上,对于交通流数据而言,总可以找到合适的阈值和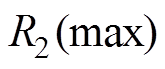 ,使得质量较高的交通流数据满足
,使得质量较高的交通流数据满足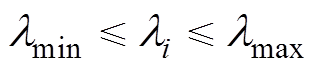 。因此,通过设置合适的阈值或便可判断出交通流数据中的异常数据序列。而对异常数据的处理方法,如移动平均法、指数平滑法、卡尔曼滤波法等已较为成熟,本文不再赘述。
。因此,通过设置合适的阈值或便可判断出交通流数据中的异常数据序列。而对异常数据的处理方法,如移动平均法、指数平滑法、卡尔曼滤波法等已较为成熟,本文不再赘述。
3 应用实例
3.1 数据来源
为验证灰色清洗规则的有效性及适用范围,探索实现无检测器道路交通流数据质量管理的一种新途径。本文选用文献[24]附录A中实际浮动车的原始数据进行实验,部分数据如表2所示。
表2 浮动车部分原始数据
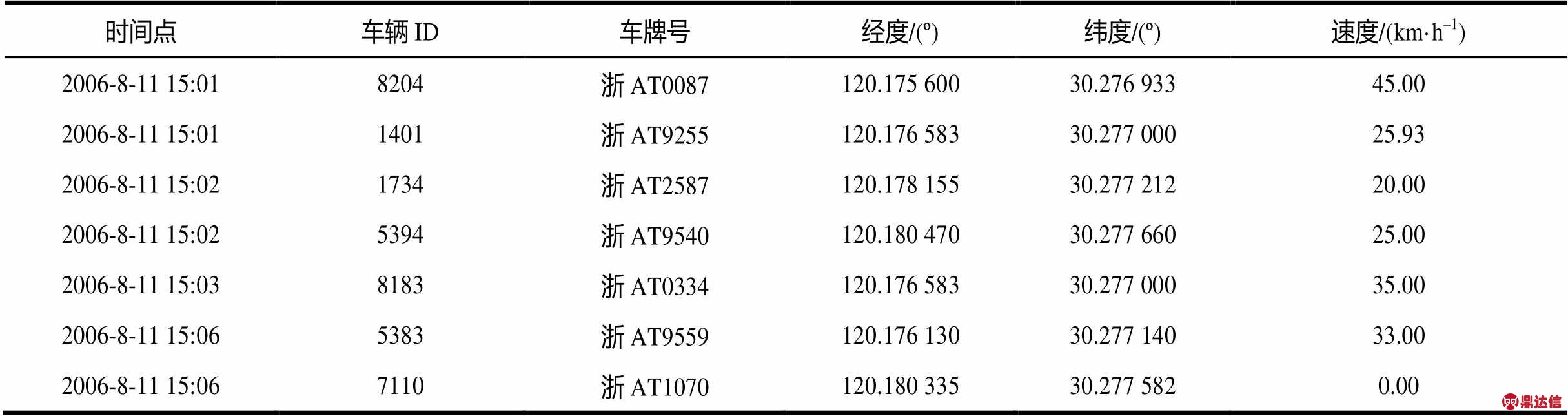
令浮动车交通流数据的速度、经度和纬度构成一个数据序列。其中,xi是第个检测点的数据序列; 分别代表第个检测点交通流数据的速度、经度和纬度值。结合文献[24]知:= 78,
分别代表第个检测点交通流数据的速度、经度和纬度值。结合文献[24]知:= 78, =10,=120.245 253,
=10,=120.245 253,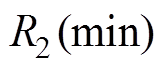 =120.170 070,
=120.170 070,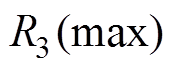 =30.289 044,
=30.289 044,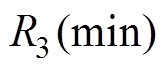 =30.274 070。
=30.274 070。
3.2 对比实验
将文献[24]附录A中浮动车的原始数据分为正常数据序列和异常数据序列(速度小于10 km/h的数据),需要说明的是此处使用文献[24]中的异常数据序列指浮动车交通流数据的经度、纬度均在正常范围内,而仅仅表现出速度的异常(如>78km/h 或<10 km/h。由于文献[12]中提出的基于相似系数和的交通流异常数据检测方法,同样适用于多属性的交通流数据质量检测,因此将其与本文提出的方法进行了对比实验。
首先,在文献[24]附录A中浮动车原始数据基础上设计10组异常数据序列,包括速度大于78 km/h的5组数据和速度小于10 km/h的5组数据;其次,根据本文提出的方法和文献[12]提出的方法分别计算每组数据的,如表3所示。最后,根据计算的λi选取阈值λ。
表3 10组异常数据序列引入正常数据序列中计算的λi
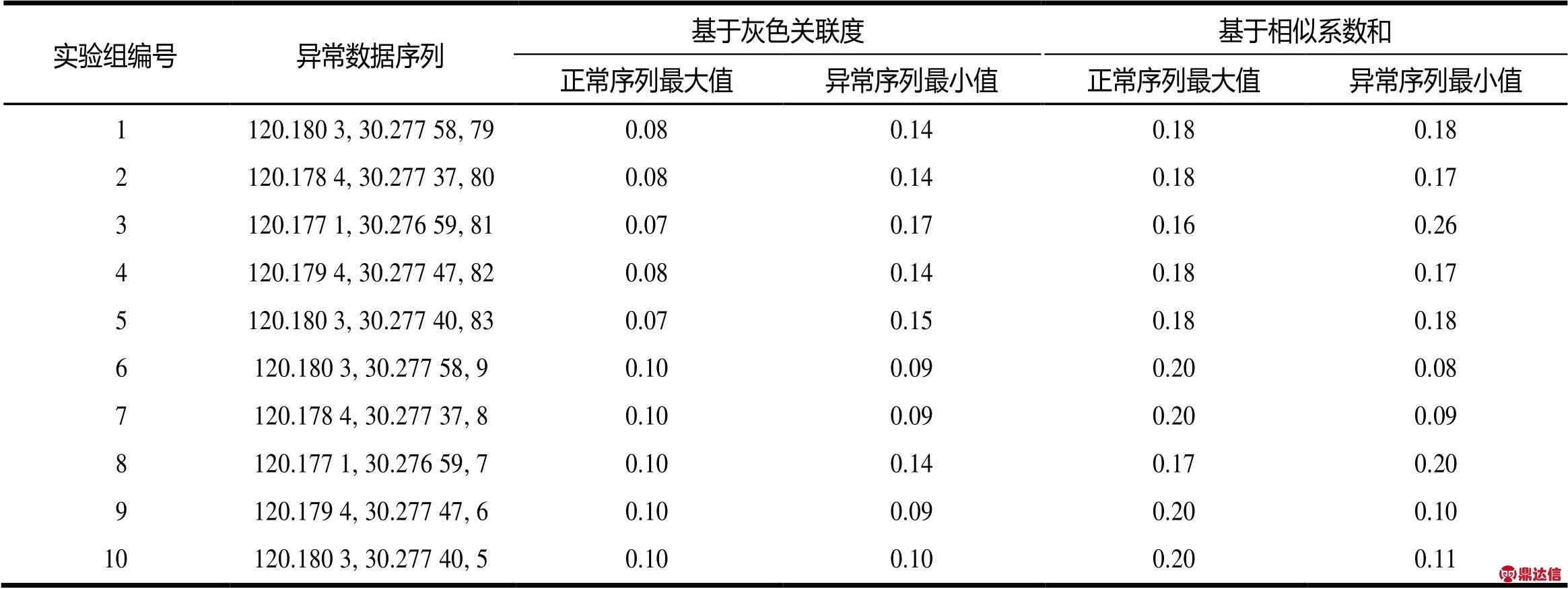
按照最大程度检测异常数据序列的原则,结合表3中的λi值,对基于灰色关联度的检测方法取阈值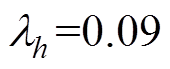 ,对基于相似系数和的检测方法取阈值
,对基于相似系数和的检测方法取阈值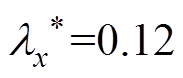 。为便于比较,采用文献[13]中提出的检测率、错检率和准确率3个指标评价这2种方法。根据2种方法对10组数据序列λi的计算结果,整理可得表4。求得正常数据序列总个数为30;实际异常数据序列总个数为1;正确检测出异常数据序列个数为1。
。为便于比较,采用文献[13]中提出的检测率、错检率和准确率3个指标评价这2种方法。根据2种方法对10组数据序列λi的计算结果,整理可得表4。求得正常数据序列总个数为30;实际异常数据序列总个数为1;正确检测出异常数据序列个数为1。
表4 存在单个异常数据序列时的检测结果对比
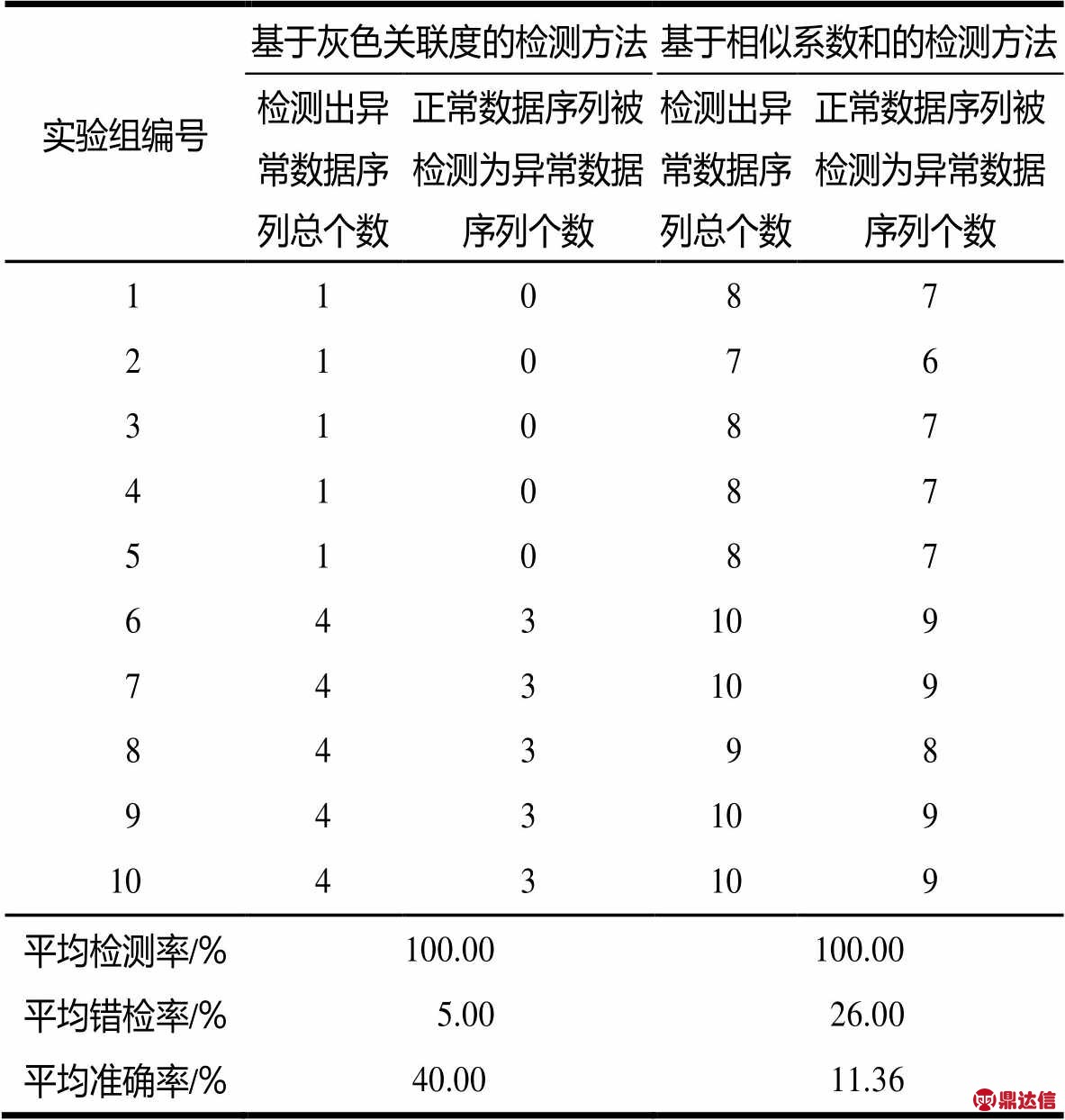
因为是按照最大程度检测异常数据序列原则选取的阈值,所以2种方法的平均检测率均为100%,即均能正确检测出实际异常数据序列个数。而平均错检率、平均准确率是由式(4)求得,即:
 (8)
(8)其中,s=10。由表4结果可知,本文基于灰色关联度提出的浮动车交通流数据质量检测方法的效果明显优于基于相似系数和的检测方法,表现为前者的平均错检率较后者降低了21.00%,前者的平均准确率较后者提高了28.64%。
考虑到文中是基于灰色自关联矩阵提出的灰色清洗规则,因此,异常数据序列的多少会对整个数据序列间的灰色关联度产生影响。为进一步检验多个异常数据序列同时存在于正常数据序列中时2种方法的优劣程度,对速度大于78 km/h的5组数据序列进行二次分组,根据2种方法计算的结果,整理可得表5。
表5 4组异常数据序列引入正常数据序列中计算的λi
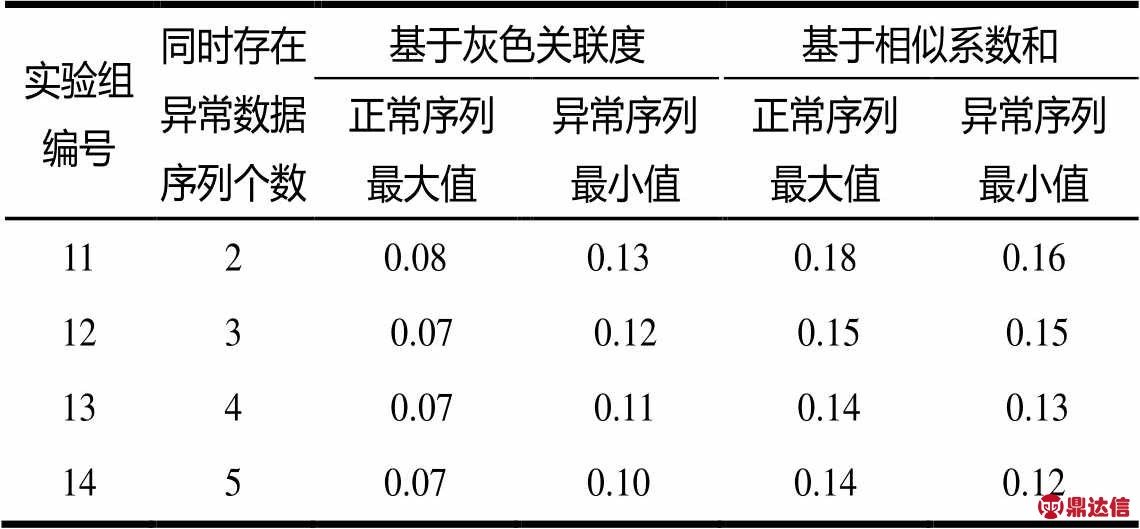
同样按照最大程度检测异常数据序列的原则,结合表5中的,对基于灰色关联度的检测方法取阈值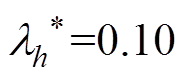 ,对基于相似系数和的检测方法取阈值,进一步整理可得表6。
,对基于相似系数和的检测方法取阈值,进一步整理可得表6。
表6 同时存在多个异常数据序列时的检测结果对比
由表6的结果可知,当多个异常数据序列同时存在时,本文基于灰色关联度提出的检测方法效果同样优于基于相似系数和的检测方法,表现为前者的平均错检率(0)小于后者的平均错检率(5%)、前者的平均准确率(100%)明显大于后者的平均准确率(70%)。同理,对速度小于10 km/h的 5组数据序列分组实验的结果同样显示,本文提出的检测方法效果优于基于相似系数和的检测方法,表现为前者的平均错检率较后者下降了13.33%,且前者的平均准确率较后者提高了13.85%。
3.3 方法有效性检验
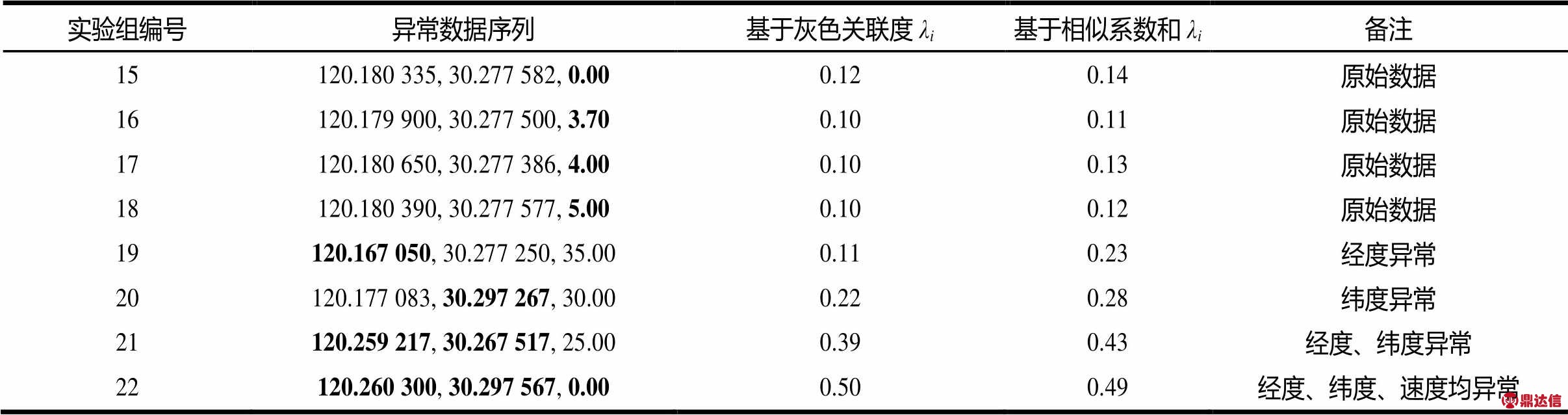
在确定基础上,使用文献[24]附录A中浮动车部分原始数据及设定异常数据对2种方法的有效性进行检测,结果如表7和图2所示,加粗为异常数据。
表7 2种方法检测有效性对比结果
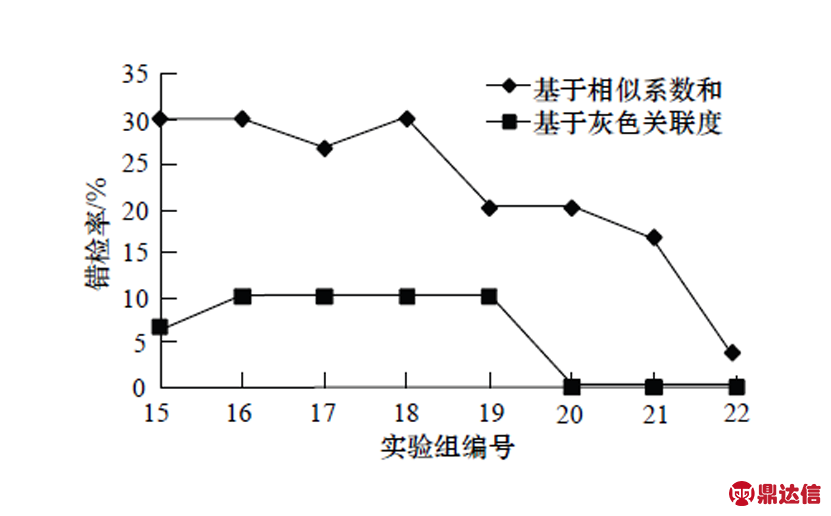
图2 交通流异常数据错检率对比
表7的数据显示,在给定阈值的情况下,2种方法均能检测出异常数据。但从图2不难发现,与基于相似系数和的检测方法相比,本文基于灰色关联度提出的无检测器道路交通流检测方法表现出更好的稳定性,且错检率小,可靠性高。
4 结束语
本文提出的灰色清洗规则综合考虑了无检测器道路交通流数据的灰色特征、多属性和随机性,为解决无检测器道路交通流数据(浮动车数据)质量问题,克服因交通流数据多属性而逐一检测所引起的时间复杂度增加和多属性间关联割裂等问题提供了一种新的思路。
对比实验结果表明,较已有的基于相似系数和的检测方法,本文基于灰色关联度提出的无检测器道路交通流检测方法表现出更好的稳定性、更高的有效性和准确性。另外,由于需求、道路等级及相关交通参数等的不同,阈值的选择也会不同,如3.2节中单个异常数据序列与多个异常数据序列2种情况的阈值选择便不相同。因此,下一步将研究如何科学地确定阈值,进而能更有效地检测出无检测器道路交通流中的脏数据。


