
摘 要:为有效解决PT燃油系统进油油路堵塞、滤清器泄漏、喷油器油路堵塞等多种典型故障诊断问题,提出了基于核主元分析(KPCA)和最小二乘支持向量机(LSSVM)的故障识别方法。首先计算油压信号的时域特征集,然后采用KPCA对原始多维初始特征向量进行特征提取,最后将经过KPCA提取的主特征向量输入经多种群遗传算法(MPGA)优化的LSSVM中实现故障类型的识别。实验结果表明,KPCA提取的主特征向量有效表达了原始故障的特征信息,相比于传统的BP神经网络和未经参数优选的LSSVM等分类模型,基于KPCA-LSSVM的故障识别方法速度更快、分类准确率更高。
关键词:PT燃油系统;核主元分析;最小二乘支持向量机;多种群遗传算法;故障诊断
PT(pressure time)燃油系统的柴油发动机已广泛应用于重型卡车、客车、轻型商用汽车等公路用车辆以及工程机械、矿山设备、铁路和军用市场等非公路领域[1]。PT燃油系统的复杂性和精密性对故障诊断提出了更高的要求。
目前对于燃油系统的故障诊断主要集中在基于模型[2]、基于神经网络和基于证据理论[3]等方法上。但大量研究表明,基于模型的故障诊断方法对模型的精确性提出了很高的要求,而且随着目前现代设备的复杂化和非线性化,想建立较为精确的数学模型变得越来越难。基于神经网络的故障诊断方法虽然应用较为广泛,但在网络模型的训练过程中存在训练时间长、模型效果过于依赖样本的数量和质量等问题。最小二乘支持向量机(least squares support vector machine,LSSVM)是对标准支持向量机的改进算法,在模型的构建和求解过程中具有运算速度快、抗噪能力强、对样本的数量要求不高等优点[4-5],在实际工程中有着广泛的应用。文献[6]采用核主元分析(kernel principal components analysis,KPCA)和LSSVM相结合的方法,有效实现了对火电厂磨煤机的早期故障预测和故障类型的判断。文献[7]采用局部均值分解、主成分分析和LSSVM方法进行了滚动轴承运行状态的安全域估计以及不同工作状态的识别。
但在LSSVM实际应用过程中,其核函数参数σ及正则化参数γ的选择对其模型的分类性能有重大影响。本文采用多种群遗传算法(multiple population genetic algorithm,MPGA)[8]对LSSVM的参数进行寻优,以达到提高模型分类性能的目的。
针对采集的PT燃油系统故障模式数据少、数据间存在较强的非线性关系的特点,文中采用KPCA方法[9]进行原始特征参数的提取,并采用经MPGA进行参数优选的LSSVM模型进行故障识别,充分发挥KPCA的非线性特征提取能力和LSSVM的小样本泛化特性,实现对发动机PT燃油系统不同工作状态的准确识别,为燃油系统的状态监测和故障诊断系统的建立提供新思路和新方法。
1 KPCA-LSSVM故障诊断模型
1.1 最小二乘支持向量机
LSSVM是SVM的改进算法,它建立在统计学习理论和结构风险最小化的基础上,其核心思想是采用最小二乘线性系统作为损失函数,替代标准SVM中的二次规划方法,这样就把原来的求解二次规划问题转换为求解线性方程组问题,简化了计算复杂性,收敛速度快。LSSVM识别模型已经成功应用于各种领域。
1.2 核主元分析
主元分析(pricipal components analysis,PCA)是一种最为常用的特征提取方法[10],但从本质上讲它是一种线性映射算法,在处理非线性问题时,往往不能取得好的效果[11]。KPCA是借助核方法将输入空间映射到一个高维Hilbert空间,然后在高维空间使用PCA法提取主成分。限于篇幅,LSSVM和KPCA算法的具体运算过程[5-7]文中不再赘述。
1.3 LSSVM参数优选
对于LSSVM的参数优选问题,目前通常采用参数穷尽搜索方法,即对LSSVM的核函数参数σ及正则化参数γ在一定范围内取值,对于取定的σ和γ,把训练集作为原始数据集,利用交叉验证的方法得到在此组σ和γ的训练集经验分类准确率。
虽然该方法能够找到在交叉验证模式意义下的最高分类准确率,但在更大范围内寻找最佳的参数σ和γ会很费时。鉴于MPGA的诸多优点[12],本文采用该方法进行LSSVM参数的寻优,限于篇幅,MPGA的原理[8]文中不再赘述。
由于KPCA和LSSVM的结合能充分发挥各自的优势,提高故障诊断的实时性和有效性,本文建立了KPCA-LSSVM的故障诊断模型,算法原理如图1所示。
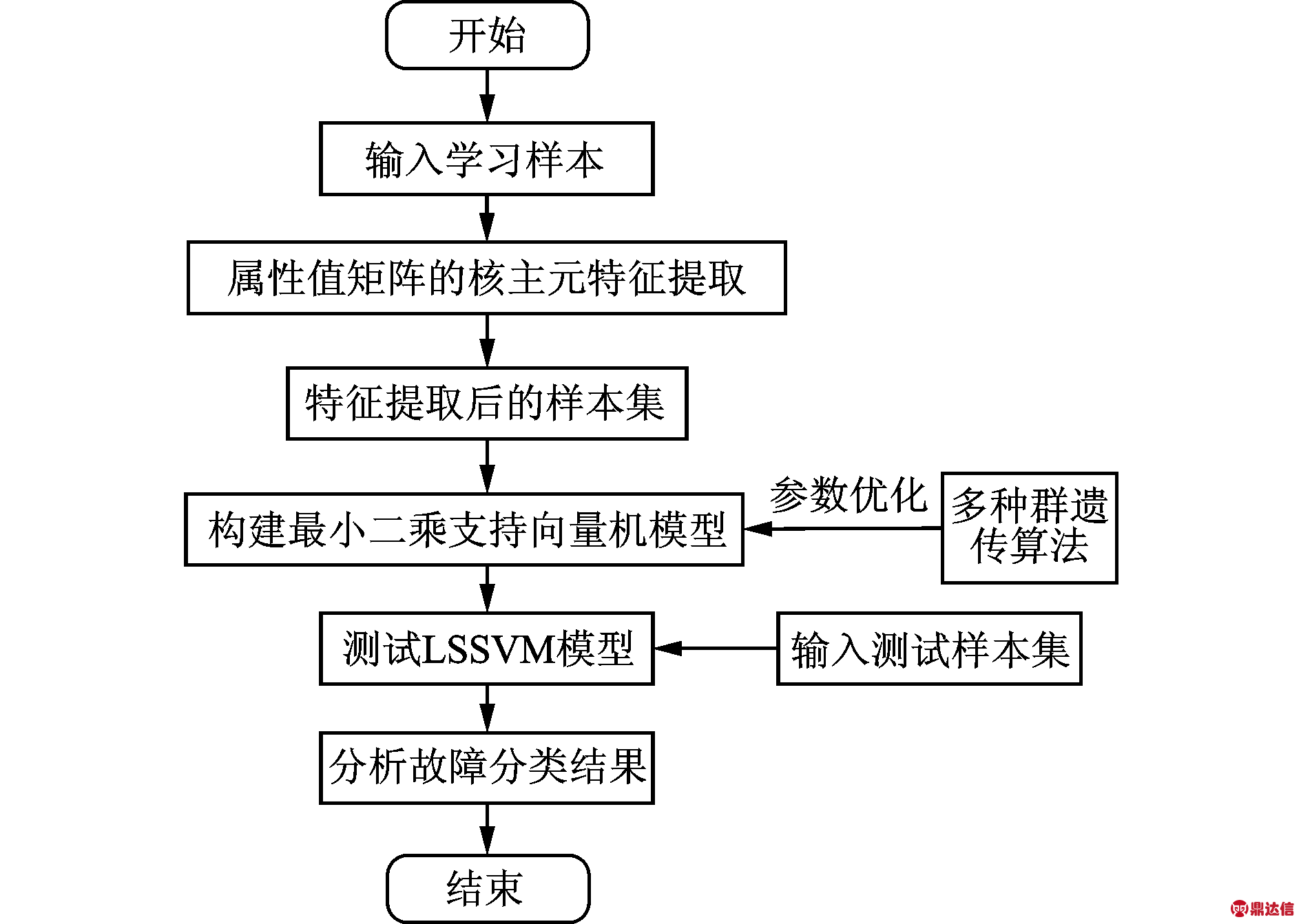
图1 KPCA-LSSVM算法流程
Fig.1 Flow chart of KPCA-LSSVM algorithm
2 PT燃油系统故障分类模型构建
2.1 故障影响因素分析
PT泵出油口的压力参数是一个非常敏感的参量,无论是PT泵进油口发生堵塞,还是PT喷油器油路发生泄漏,均可以在泵出油口的压力参数上得到体现。因此本文采集5种故障状态下的PT泵出油口压力参数作为训练样本,其中将PT燃油系统正常工作状态作为一种特殊的故障状态。利用KPCA-LSSVM建立多因素与相应结果之间的非线性关系来构建故障多分类模型,实验设备采用自行研制的JCPS01型PT泵试验台,实验原理如图2所示。
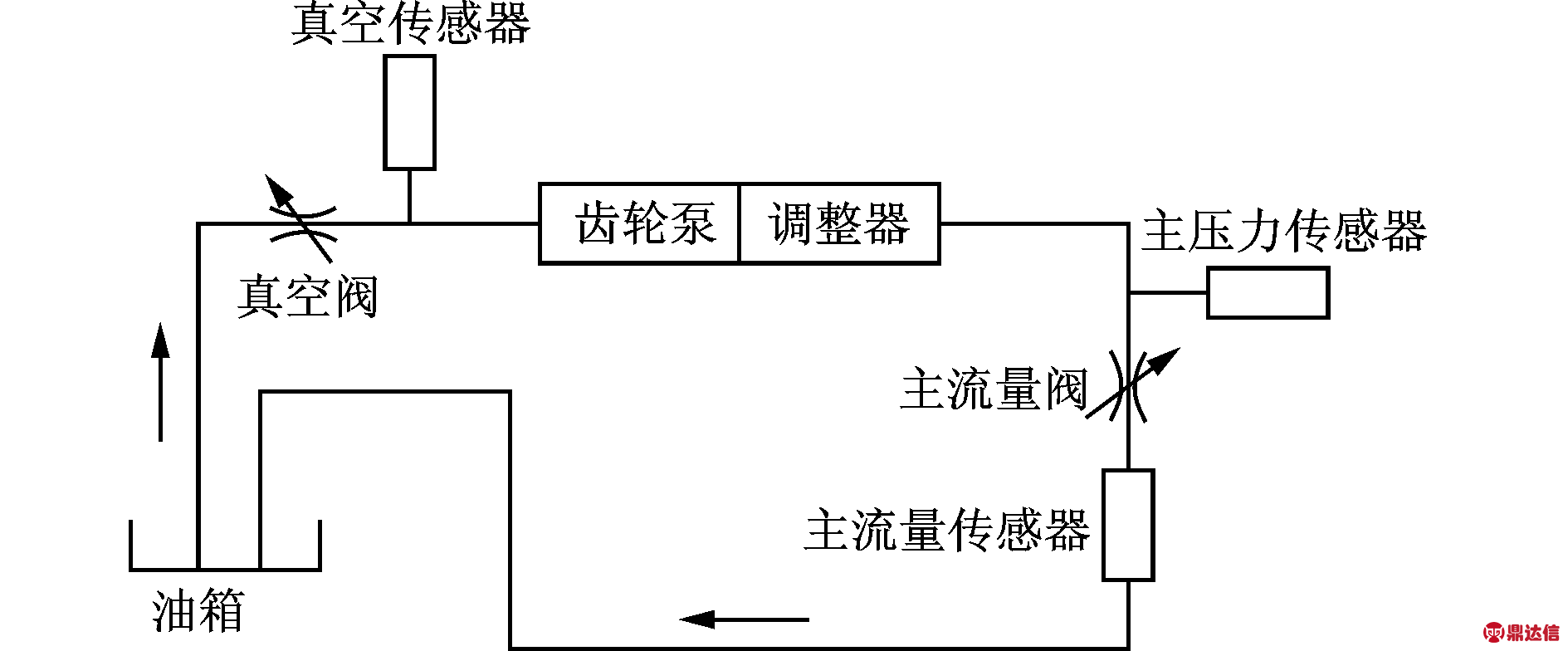
图2 实验原理
Fig.2 Experimental principle
实验中用真空阀的打开和关闭模拟PT泵进油滤清器泄漏和油路堵塞2种工作状态,用主流量阀的打开和关闭模拟喷油器油路泄漏和油路堵塞2种工作状态。当PT泵转速为1 800 r/min,主压力达到0.72 MPa时视为PT泵的正常工作状态。分别测量正常情况(故障模式1)、PT泵进油油路堵塞(故障模式2)、滤清器泄漏(故障模式3)、喷油器油路堵塞(故障模式4)、喷油器油路泄漏(故障模式5)情况下PT泵出油口的压力信号。在实验中,每种工作状态下的油压数据采集了30组,共计150组数据,在进行后续的工作状态识别时,每种工作状态数据随机选择20组作为训练样本,剩余10组作为测试样本。各种状态的信号经数学形态学[13]去噪处理后,得到的一组去噪信号如图3所示。
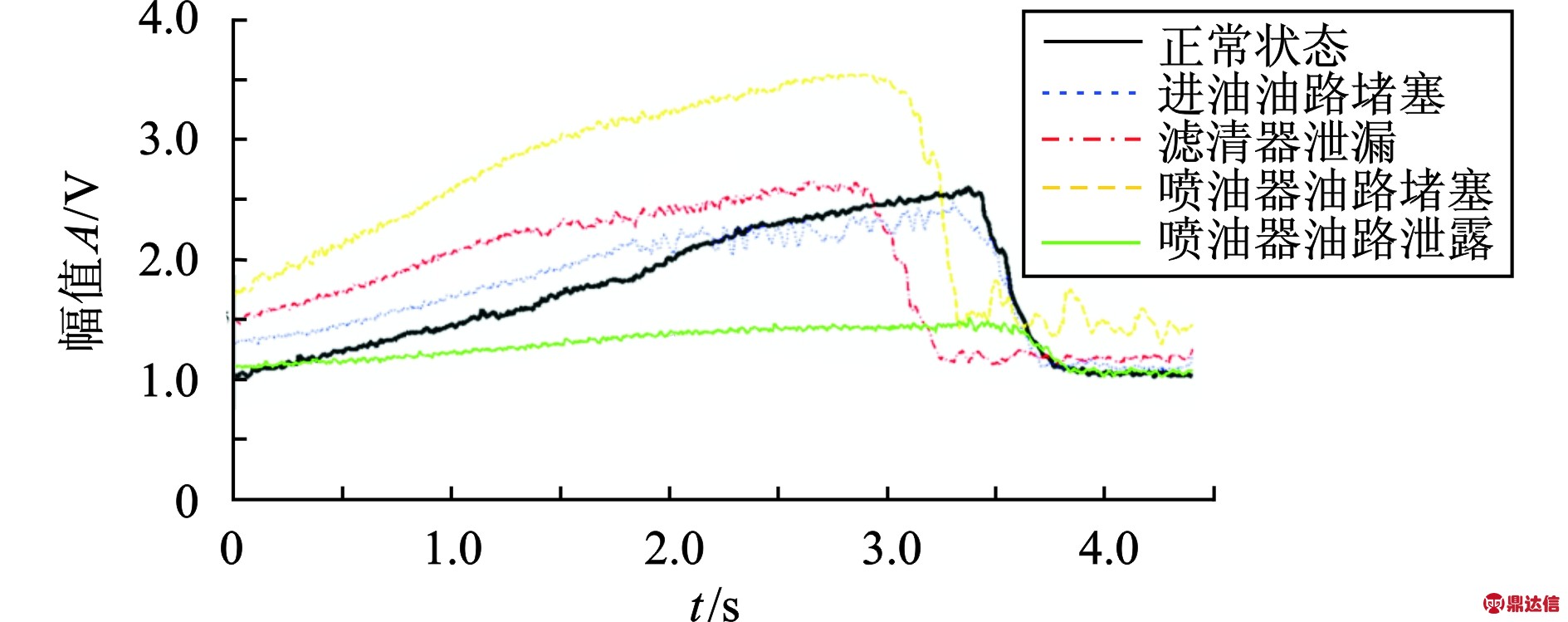
图3 去噪后各个状态的油压信号
Fig.3 Denoising signals of different conditons
2.2 实验数据的处理
PT泵出油口压力波动情况主要取决于系统的工作状态,由于采集的油压信号不具备明显的频域特征,因此在信号处理时主要采用时域分析的方法。
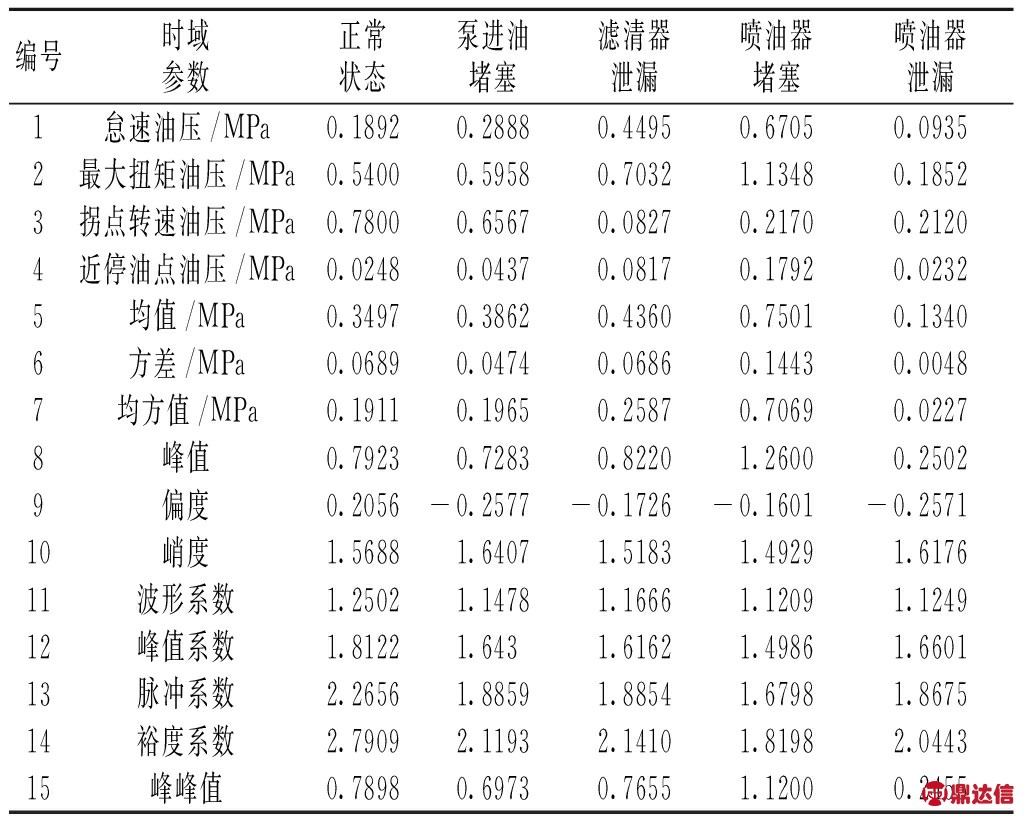
以正常状态的PT泵出油口压力信号为依据,分别提取怠速点油压(转速550 r/min)、最大扭矩点油压(转速1 200 r/min)、拐点转速油压(转速1 830 r/min)及近停油点油压(转速2 200 r/min)作为4个特征值。这4个特征值能够描述各种状态下信号的轮廓,然后计算不同状态油压信号的均值、方差、均方值、峰值、偏度、峭度、波形系数、峰值系数、脉冲系数、裕度系数及峰峰值11个时域特征参数[14],共计15个特征值。其中一组数据的特征值如表1所示。
表1 各种工作状态下信号的时域特征参数
Tab.1 Parameters of time-domain characteristic at different working conditions
5种不同工作状态的部分时域特征值如图4所示。比较图4中不同工作状态的特征值分布可以发现,不同工作状态的部分特征值差距不是很明显,如图4(a)所示,对于滤清器泄漏、喷油器堵塞和喷油器泄漏3种故障,其拐点转速油压值都分布在0.1~0.2 MPa,差距不是很明显。
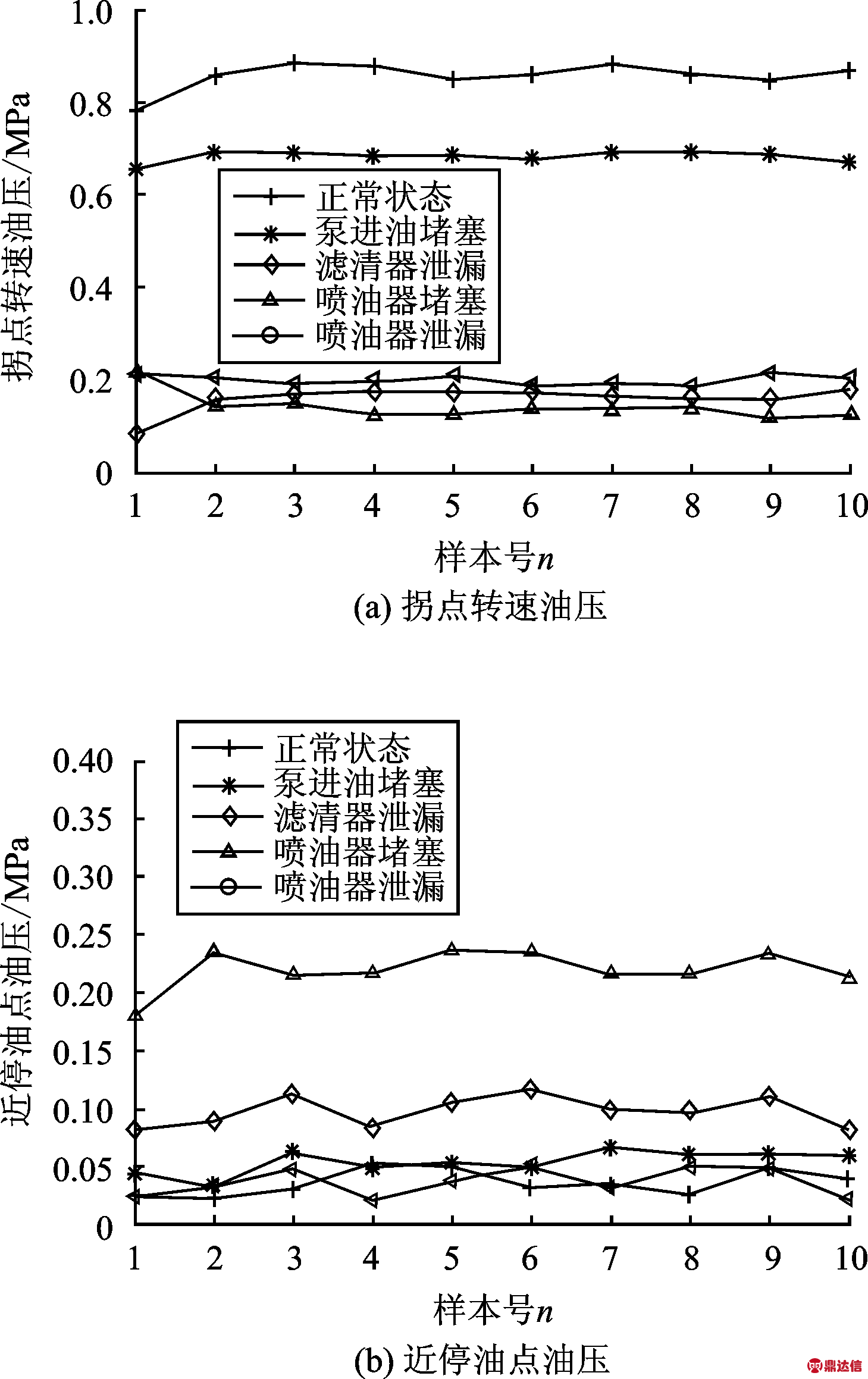
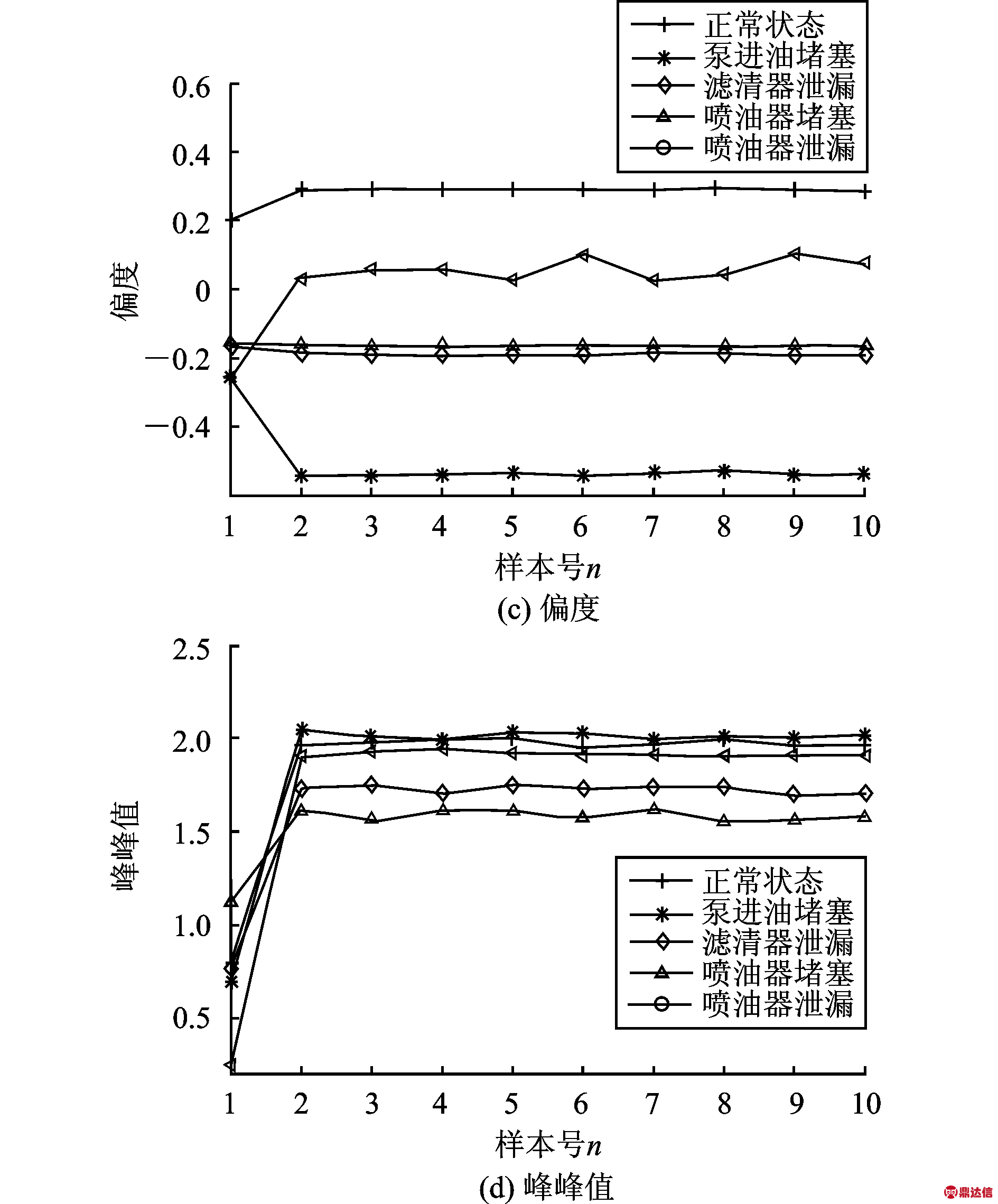
图4 不同工作状态下部分特征值分布
Fig.4 Some characteristic values at different working conditions
部分特征值存在交叉重叠的现象,如图4(b)所示,对于正常状态、泵进油堵塞和喷油器泄漏3种故障,其近停油点油压值在0.025~0.075 MPa存在交叉重叠的现象。因此,任何单一的特征参量都无法准确区分PT燃油系统的工作状态,为此需要进行多特征参数的融合,消除多特征值之间的重叠和交叉,提高识别的准确性。
采用高斯核的KPCA算法对原始特征矩阵进行特征提取,原始特征矩阵在经过标准化后,计算核矩阵、中心化核矩阵,得到矩阵特征值、各成分的贡献率以及累计贡献率如表2所示。
表2 样本特征值对应的贡献率及累计贡献率
Tab.2 Contribution and accumulation contribution rate of characteristic values
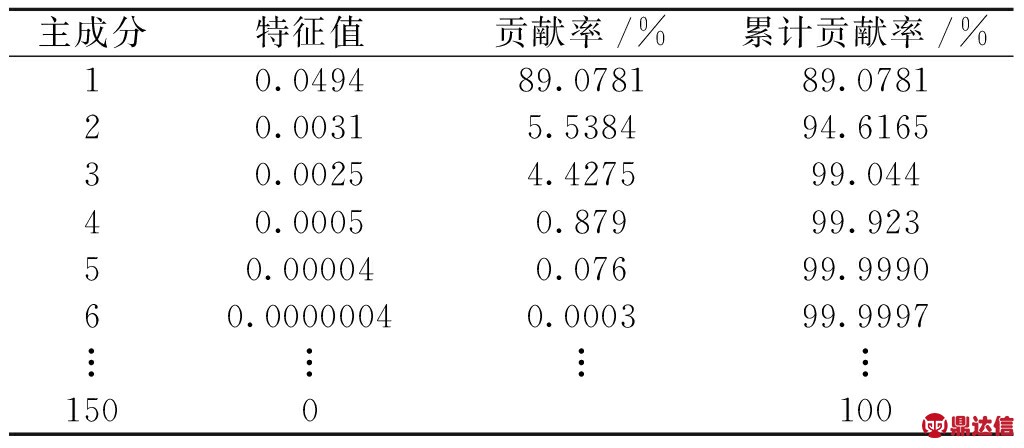
从表2可知,经KPCA提取的前2个主成分的累积贡献率为94.616 5%,达到了表达原始特征矩阵的目的。为此,文中选用主成分1和主成分2作为新的组合特征对PT燃油系统不同的工作状态进行识别。前2个主成分累积贡献率如图5所示。
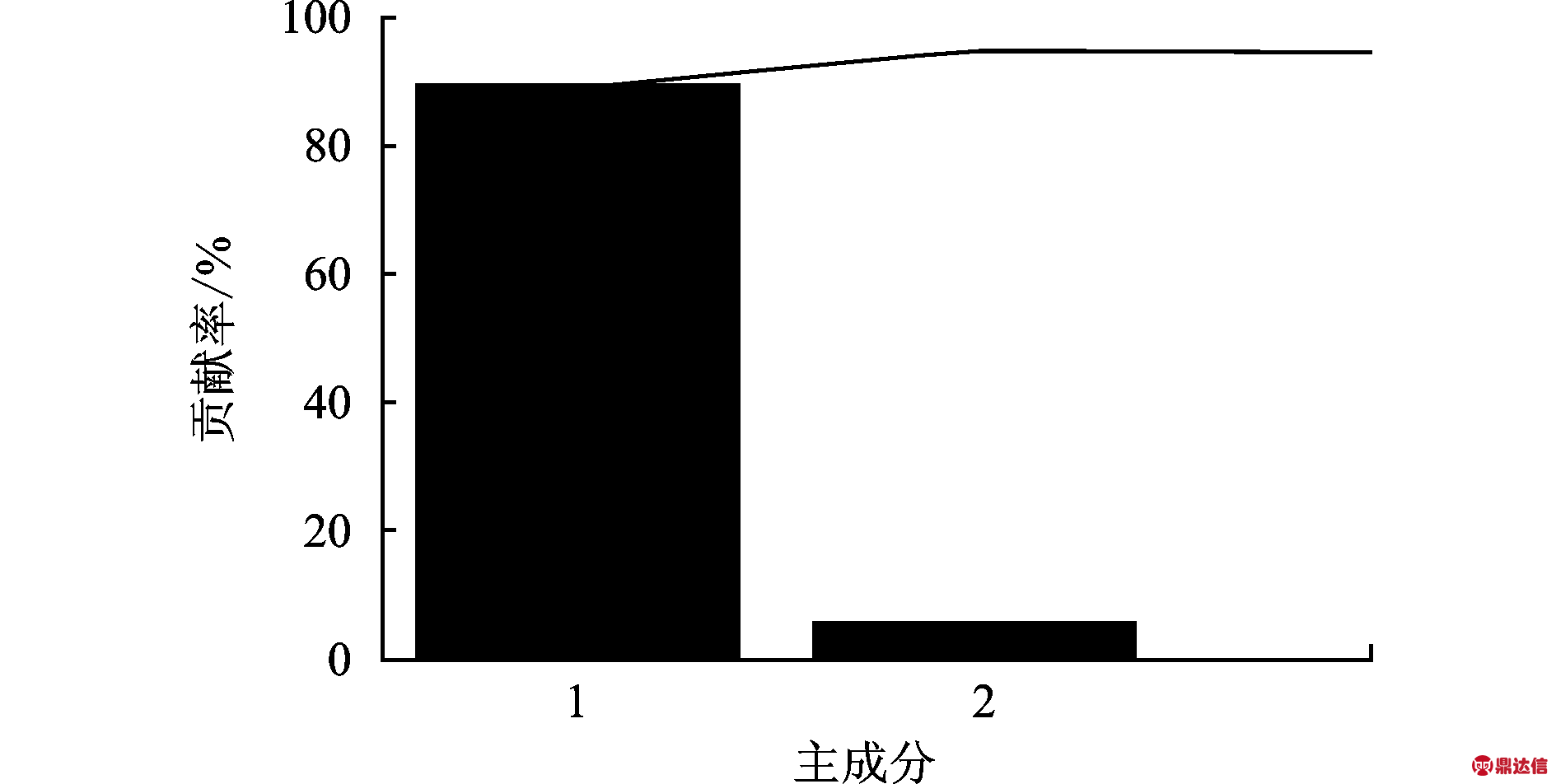
图5 前2个主成分累积贡献率
Fig.5 Accumulation contribution of the first two principal components
为了更直观地显示经KPCA特征提取后的效果,本文将提取的前2个主成分投影到二维平面显示,所有训练样本前2个主成分的二维分布效果如图6所示。
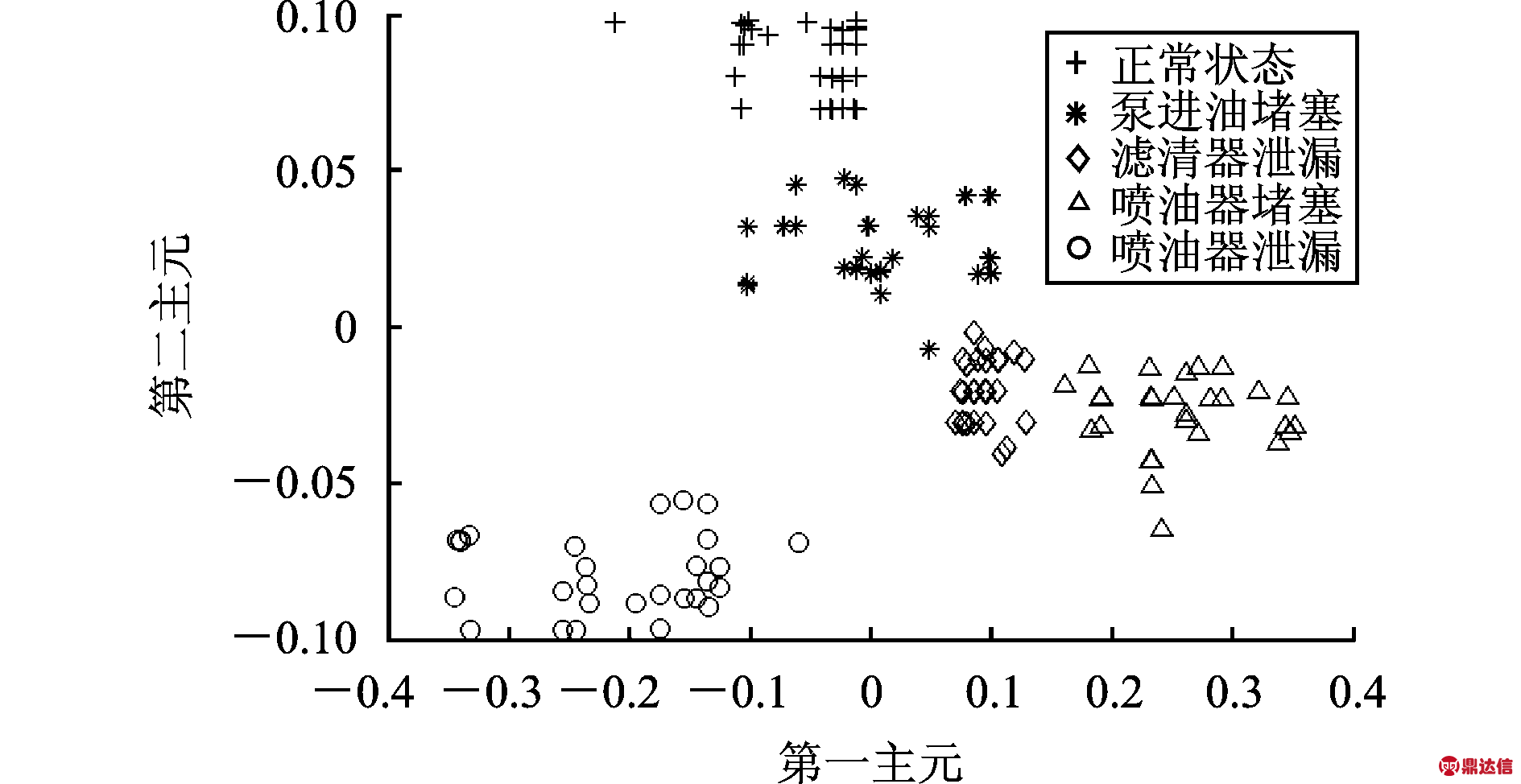
图6 前2个主分量的二维分布
Fig.6 2-D numerical distribution of the first two principal components
由图6可知,经过KPCA处理后,其核主成分具有较好的聚类性能,提取的综合特征值分布区间明显,不同类别样本间的可分性明显变好。所有样本的综合特征参数如表3所示。
为了检验文中所提算法的性能,本文采用其他2种不同的分类模型与其作对比,其中BP神经网络结构为3层,隐含层激活函数为双曲正切函数,隐含层神经元的个数是经网络训练误差对比确定的,输出层采用线性激活函数。不同的分类模型、模型的参数以及分类结果如表4所示。
表3 模型的训练样本和预测样本
Tab.3 Training and forecasting samples of model
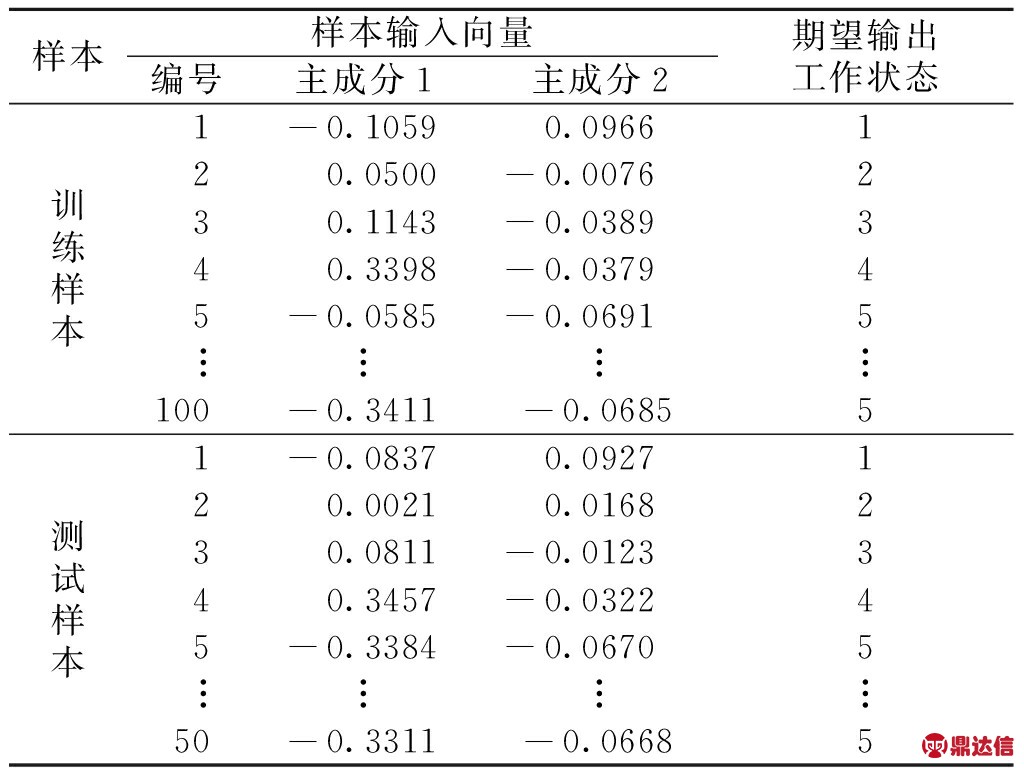
表4 3种方法的对比结果
Tab.4 Comparison results of different methods
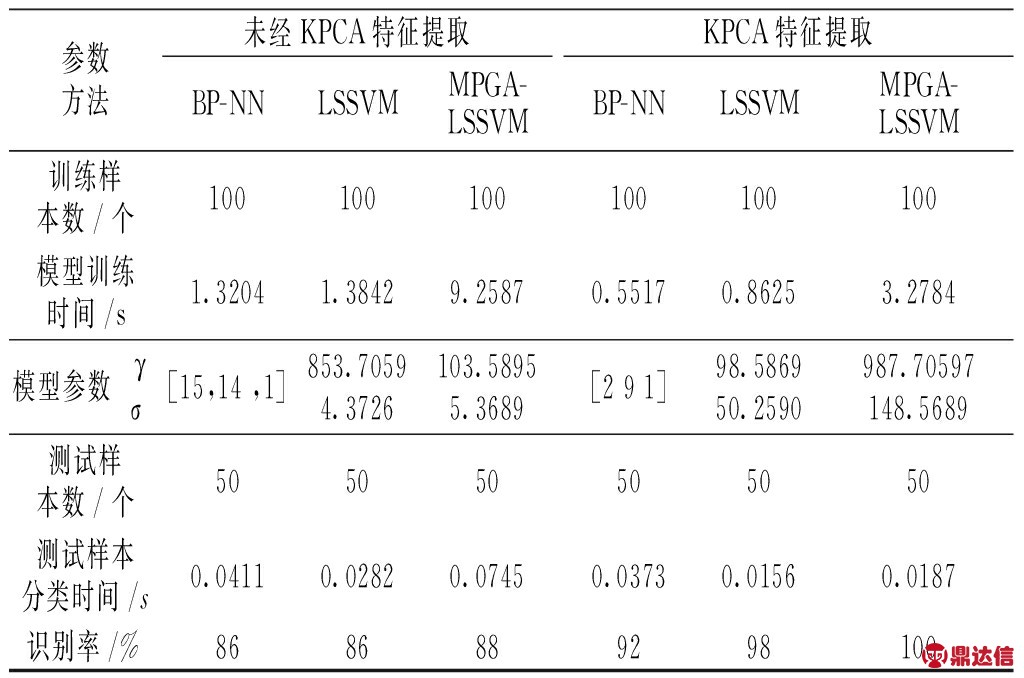
由表4可知,与KPCA特征提取后的模型相比,在未经KPCA提取的情况下,分类模型的训练时间与测试样本的分类时间均较长且识别率不高。本文并未与其他特征提取算法进行对比,比如粗糙集、主元分析等,这些方法的对比将在后续研究工作中开展。
比较经参数优化的LSSVM分类模型的识别结果可以看出,经过参数优化后,分类模型的识别率提高了,减少了模型在选择参数上的盲目性。同时,LSSVM模型和MPGA-LSSVM模型的识别率都大于BP神经网络,这也充分体现了LSSVM针对小样本统计和预测学习方面的优越性。而BP-NN算法由于过分依赖模型训练过程中样本数据的数量和质量,因此在本文训练样本数据数量较小的情况下,故障识别率较低。
3 结论
针对PT燃油系统故障样本数据数量小、不具备明显频域特征以及分类器参数选择的问题,提出了KPCA和MPGA-LSSVM相结合的PT燃油泵故障诊断方法。主要结论如下:
(1)PT燃油系统油压信号为典型的非平稳信号,不具备明显的频域特征,且不同工作状态下的时域特征参数存在交叉重叠的现象,单一特征参量无法准确识别燃油系统的工作状态。
(2)针对PT燃油系统油压信号时域特征的特点,利用KPCA进行特征参数提取,消除了不同时域特征值之间存在的交叉重叠现象,简化了分类器结构,提高了模型识别的准确率。
(3)针对LSSVM参数选择问题,采用MPGA群智能算法进行参数的优选。通过对比BP-NN、未经参数优选的标准LSSVM以及有没有经过KPCA进行特征提取等多种分类模型的识别结果,说明了经过KPCA特征提取和经MPGA参数优选的LSSVM分类模型具有更快的诊断速度和更高的准确率,具有更强的工程实用性。


